
Die Aufnahmen für meine Beiträge produziere ich meistens spontan. wenn halt gerade Zeit ist. Was auch heißt, dass der Zustand meiner Schleimhäute und Lippen eher weniger kontrolliert ist. Da gibt es dann Schmatzer, Lippenclicks und ähnliche Störgeräusche. Auf dem Markt für VST-Plugins gibt es eine Menge Angebote zum Bereinigen solcher Ausrutscher, wie das RX-100-Paket von iZotope. Sicher sind diese Tools oft effektiver als handgemachte Sachen. In Adobe Audition habe ich die Sache jedoch inzwischen ganz gut in den Griff bekommen. Denn mit einem DeClicker kann man allzu vorlaute Mundgeräusche grundsätzlich in den Griff bekommen. Inzwischen habe ich alle Effekte, die ich regelmäßig benutze, in einer Funktion zusammengeführt.
Posts

Eine Zeit lang habe ich gerne mit dem Rode NT1-A aufgenommen. Die eine Stärke des Kondensator-Großmembraners ist das fast nicht hörbare Rauschen. Die andere ist für die Aufnahme von Gesang die Fähigkeit, auch kleinste Nuancen und Feinheiten aufzulösen, für eine Sängerin wie Adele unverzichtbar, für einen Sprecher von Texten jedoch eher nervig. Denn diese Feinsinnigkeit des NT1-A bedeutet, dass auch kleinste Unsauberkeiten wie Lippengeräusche, Schmatzen, Zungengeräusche oder nur Geräusche von der Maus in der Aufnahme landen. Das nervte mich. So holte ich wieder mein Rode Procaster aus dem Koffer, stöpselte den geliebten Triton FetHead davor und erfreute mich des warmen, angenehmen Klanges dieses mächtigen Großmembraners der dynamischen Bauweise. Keine Schmatzer mehr, keine Lippengeräusche, ein sonorer Klang, der trotzdem nicht auf Feinheiten in der Stimme und Artikulation verzichtet. Aber oh weh, da war es wieder. Wenn man sich keinen Channel Strip (also einen Mikrofon-Vorverstärker) der 2000 Euro-Klasse leisten kann oder will, ist es so sicher wie das Amen in der Kirche: das Rauschen vom Mikrofon selbst und vom Vorverstärker. Denn aufgrund physikalischer Gegebenheiten rauscht gerade ein dynamisches Mikro eben. Der Kondensator hat da prinzipbedingt die Nase vorn. Also entweder es rauschen lassen, oder … sich etwas detaillierter mit den Rauschreduzierungen in Adobe Audition auseinander setzen. Gesagt, getan. Die Zeit kostet das Erforschen, wie es geht. Hat man das getan, ist das weitgehende Ausschalten des Rauschens nur eine Sache weniger Clicks.
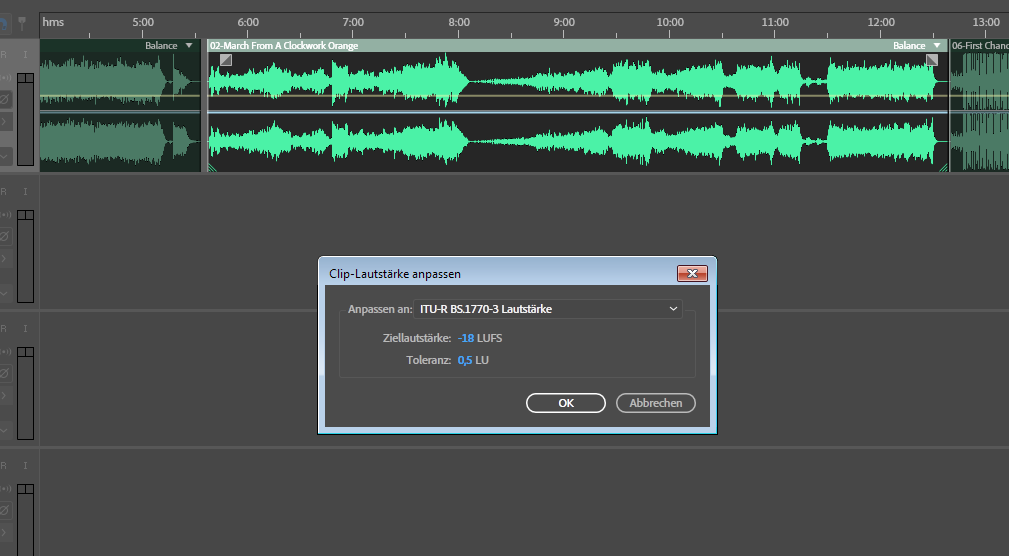 Eine wiederkehrende Situation sind Sendungen mit Musikstücken aus verschiedenen Quellen und aus verschiedenen Zeiten. Während das alte Supertramp-Album relativ leise ist, haut ein Metallica-Stück danach die Membranen aus den Lautsprechern. Mein erster Ansatz war, jeweils ein Stück über das Kontextmenü unter der rechten Maustaste auf eine bestimmte Loudness zu bringen. Das dann halt für jedes Stück. Neben der Zeit, die das Verfahren benötigte, war das auch sonst kontraproduktiv. Beim finalen Abhören der gesamten Sendung waren dann doch wieder Unterschiede in der Lautheit zu hören, weil zwar die absolute Lautheit jedes einzelnen Stücks gesetzt war, aber nicht in Relation aller beteiligten Stücke. Dazu hat Audition nämlich ein spezielles anderes Tool an Bord.
Eine wiederkehrende Situation sind Sendungen mit Musikstücken aus verschiedenen Quellen und aus verschiedenen Zeiten. Während das alte Supertramp-Album relativ leise ist, haut ein Metallica-Stück danach die Membranen aus den Lautsprechern. Mein erster Ansatz war, jeweils ein Stück über das Kontextmenü unter der rechten Maustaste auf eine bestimmte Loudness zu bringen. Das dann halt für jedes Stück. Neben der Zeit, die das Verfahren benötigte, war das auch sonst kontraproduktiv. Beim finalen Abhören der gesamten Sendung waren dann doch wieder Unterschiede in der Lautheit zu hören, weil zwar die absolute Lautheit jedes einzelnen Stücks gesetzt war, aber nicht in Relation aller beteiligten Stücke. Dazu hat Audition nämlich ein spezielles anderes Tool an Bord.
 Das Thema treibt mich mittlerweile in den Wahnsinn. Wie mische ich eine moderierte Sendung so ab, dass Sprache und Musik subjektiv gleich laut klingen, so dass die Sprache verständlich bleibt, man aber bei der nächsten Musik nicht gleich wieder einen Sprint ans Radio einlegen muss? Bisher bin ich das Thema weitgehend experimentell angegangen, war aber mit den Ergebnissen nicht immer wirklich zufrieden. Für mich war die Reproduzierbarkeit wichtig, damit ich nicht bei jedem neuen Beitrag wieder ans Ausprobieren komme. Die Antwort war nahe liegend, aber nicht bewusst. Ich hatte die dazu sinnvollen Tools in Adobe Audition nämlich schon lange in Gebrauch, war mir aber der Tragweite ihrer Wirkung nicht wirklich bewusst.
Das Thema treibt mich mittlerweile in den Wahnsinn. Wie mische ich eine moderierte Sendung so ab, dass Sprache und Musik subjektiv gleich laut klingen, so dass die Sprache verständlich bleibt, man aber bei der nächsten Musik nicht gleich wieder einen Sprint ans Radio einlegen muss? Bisher bin ich das Thema weitgehend experimentell angegangen, war aber mit den Ergebnissen nicht immer wirklich zufrieden. Für mich war die Reproduzierbarkeit wichtig, damit ich nicht bei jedem neuen Beitrag wieder ans Ausprobieren komme. Die Antwort war nahe liegend, aber nicht bewusst. Ich hatte die dazu sinnvollen Tools in Adobe Audition nämlich schon lange in Gebrauch, war mir aber der Tragweite ihrer Wirkung nicht wirklich bewusst.