
Podcasts mit professionellem Sound, oder wenigstens halbwegs
Seit gut zehn Jahren produziere ich Beiträge für Berliner Bürgerradios, Schwerpunkte Musik und Zeitgeschichte. Da ich aber Stunden am Tag auch Radio höre, überwiegend WDR 5 und Deutschlandfunk, hatte ich immer den Sound in den Ohren, wie die Stimmen klingen sollten. Trotz vieler YouTube-Videos zu diesem Thema, mit vielen Anleitungen im Web und in Büchern, hat es seine Zeit gedauert, bis ich “meinen” Klang bekommen habe. Ein solcher Stimmklang ist immer etwas Subjektives, und wie ich als Teamleiter der Sprecher in einer ehrenamtlichen Institution weiß, hat da jeder so seine ganz eigene Vorstellung. Mein Richtwert waren aber immer die Höreindrücke, wie ich sie im professionellen Radio, und auch Podcast, eben mitgenommen habe. Diese Lernkurve, die sich über Jahre hingezogen hat, möchte ich deshalb noch einmal zusammen fassen. Auch deshalb, weil die Vorschläge und Anleitungen in Medien für mich eben nicht funktioniert haben. Fangen wir ganz vorne an.
Der Aufnahmeraum
Als Amateur muss man sich mit den Gegebenheiten zurecht finden. Selten hat man in der Wohnung einen Raum mit optimalen Eigenschaften, welche sein sollten:
Nicht zu klein, möglichst nahe am Quadrat, längliche Räume sind nur mit hohem Aufwand akustisch sauber zu bekommen. Gut gedämpft durch Teppiche, Vorhänge, Polstermöbel; man kann mit anderen Mitteln eine Menge korrigieren, einen halligen Raum nicht; Schlafzimmer haben mit einem Bett gute Chancen. Hat es einen Nachhall, wenn man in die Hände klatscht, reicht die Dämpfung nicht; dazu sind nicht immer teure Studiomöbel notwendig, manchmal reichen einfache Dinge. Jede Investition in Noppenschaumstoff ist vergeudetes Geld; es sei denn, er ist mindestens fünf Zentimeter dick, erst dann bewirkt er etwas, aber eben nicht billig
Zum Thema Raumbehandlung gibt es eine Menge Artikel im Web, sie liegen fast alle richtig.
 Als ich in Niedersachsen wohnte, hatte ich einen fast perfekten Raum: ein großer Keller, fast alle Wände mit gut gefüllten Regalen zugestellt. Mit ein paar billigen Vorhängen von IKEA, einem dicken Teppich aus gleicher Quelle und ein paar wenige Diffusoren an der Decke wurde der Raum nicht nur wohnlich, sondern auch akustisch geeignet. Hier in Ostwestfalen hatte eine keine solche Möglichkeit, weshalb ich zum alten Reporter-Trick zurück gekehrt bin. Man glaubt nicht, wie viele Reportagen im Radio aus einem Kleiderschrank kommen. Hängen dann noch reichlich Sachen darin, räumt man eine Ecke frei und beinahe fertig ist die Sprecherkabine. Leider muss man dann mit dem EQ nachhelfen, das Thema kommt noch gleich.
Als ich in Niedersachsen wohnte, hatte ich einen fast perfekten Raum: ein großer Keller, fast alle Wände mit gut gefüllten Regalen zugestellt. Mit ein paar billigen Vorhängen von IKEA, einem dicken Teppich aus gleicher Quelle und ein paar wenige Diffusoren an der Decke wurde der Raum nicht nur wohnlich, sondern auch akustisch geeignet. Hier in Ostwestfalen hatte eine keine solche Möglichkeit, weshalb ich zum alten Reporter-Trick zurück gekehrt bin. Man glaubt nicht, wie viele Reportagen im Radio aus einem Kleiderschrank kommen. Hängen dann noch reichlich Sachen darin, räumt man eine Ecke frei und beinahe fertig ist die Sprecherkabine. Leider muss man dann mit dem EQ nachhelfen, das Thema kommt noch gleich.
Das Mikrofon
 Mittlerweile liegt eine Sammlung von acht oder neun Mikrofonen in meiner Schublade. Bei Sprechern liegt die gleiche Gefahr vor wie bei Gitarristen: Sie meinen, diese eine Gitarre/dieses eine Mikrofon löst alle Probleme und bringt einen der Glückseligkeit näher. Wobei einige dieser Mikro in der Schublade im deutlich dreistelligen Preisbereich liegen. Meine Lernkurve: keine dynamischen Mikros, die sind empfänglich für eingestreutes Netzbrummen, haben einen übermäßigen Nahbesprechungs-Effekt und sind nicht so unempfindlich für den Raum, wie immer behauptet wird.
Mittlerweile liegt eine Sammlung von acht oder neun Mikrofonen in meiner Schublade. Bei Sprechern liegt die gleiche Gefahr vor wie bei Gitarristen: Sie meinen, diese eine Gitarre/dieses eine Mikrofon löst alle Probleme und bringt einen der Glückseligkeit näher. Wobei einige dieser Mikro in der Schublade im deutlich dreistelligen Preisbereich liegen. Meine Lernkurve: keine dynamischen Mikros, die sind empfänglich für eingestreutes Netzbrummen, haben einen übermäßigen Nahbesprechungs-Effekt und sind nicht so unempfindlich für den Raum, wie immer behauptet wird.
Ich bin nach vielen Versuchen immer wieder zum Røde NT1-A zurück gekehrt. Erstaunt war ich allerdings auch, als ich ein superbilliges Mikro-Pärchen von Behringer namens C-2 für Außenaufnahmen erworben habe. Für 55 Euro (das Paar!) klingen sie nicht übel. Ein Vergleich.
 Möchte man doch ein dynamisches Mikrofon verwenden, weil man zum Beispiel noch ein gutes altes Shure SM57 im Bestand hat, muss man den Eingangsregler schon ziemlich weit aufziehen. Bei einfachen Interfaces, wie bei Steinberg oder Focusrite, kommt dann ein deutliches Rauschen ins Spiel. Hier ist mein Mittel der Wahl der FetHead, der auf einfache Weise 27 dB Verstärkung bringt und das Signal fast auf den Pegel von Kondensator-Mikrofonen hebt.
Möchte man doch ein dynamisches Mikrofon verwenden, weil man zum Beispiel noch ein gutes altes Shure SM57 im Bestand hat, muss man den Eingangsregler schon ziemlich weit aufziehen. Bei einfachen Interfaces, wie bei Steinberg oder Focusrite, kommt dann ein deutliches Rauschen ins Spiel. Hier ist mein Mittel der Wahl der FetHead, der auf einfache Weise 27 dB Verstärkung bringt und das Signal fast auf den Pegel von Kondensator-Mikrofonen hebt.
Das Interface
 Nachdem nun schon zwei Focusrite-Interfaces einfach den Betrieb eingestellt haben, verwende ich nur noch das Steinberg UR 22, das ein gutes Preis-Leistungs-Verhältnis hat und ausreichend sauber arbeitet. Abraten würde ich von der Version MKII. Aus unerfindlichen Gründen hat Steinberg bei diesem Gerät den Ausgangspegel für den Kopfhörer abgesenkt, leider auch die Empfindlichkeit des Einganges. Nicht nachvollziehbar, doch zum Ärger vieler Anwender, die noch die erste Version hatten und dann das MKII kauften. Also möglichst die alte Version nehmen, so man sie noch bekommt. Doch auch andere Hersteller liefern brauchbare Audio-Interfaces, ohne dass man einen Kredit aufnehmen muss. Zu Unrecht in Verruf geraten sind die Produkte von Behringer. Für ihren Preis sind sie wirklich brauchbar. Man kann nur nicht von einem Gerät für 50 Euro das Gleiche erwarten wie von einem Studio-Interface zum vierstelligen Preis.
Nachdem nun schon zwei Focusrite-Interfaces einfach den Betrieb eingestellt haben, verwende ich nur noch das Steinberg UR 22, das ein gutes Preis-Leistungs-Verhältnis hat und ausreichend sauber arbeitet. Abraten würde ich von der Version MKII. Aus unerfindlichen Gründen hat Steinberg bei diesem Gerät den Ausgangspegel für den Kopfhörer abgesenkt, leider auch die Empfindlichkeit des Einganges. Nicht nachvollziehbar, doch zum Ärger vieler Anwender, die noch die erste Version hatten und dann das MKII kauften. Also möglichst die alte Version nehmen, so man sie noch bekommt. Doch auch andere Hersteller liefern brauchbare Audio-Interfaces, ohne dass man einen Kredit aufnehmen muss. Zu Unrecht in Verruf geraten sind die Produkte von Behringer. Für ihren Preis sind sie wirklich brauchbar. Man kann nur nicht von einem Gerät für 50 Euro das Gleiche erwarten wie von einem Studio-Interface zum vierstelligen Preis.
Nach dem Einsprechen ist vor dem Produzieren
Da ich hier in Ostwestfalen wieder auf meinen Kleiderschrank angewiesen war, stellten mich die Aufnahmen nun vor neue Herausforderungen. Zwar ist der Schrank wegen dicker Wintermäntel recht ruhig und gedämpft, allerdings bilden sich durch das kleine Volumen Raummoden heraus, was sich in einem Dröhnen darstellte. Das war auch mit dicken Absorbern nicht in den Griff zu bekommen. Damit begann die ausgiebige Beschäftigung mit dem Equalizer.
Effektketten
Manche Leute meinen, dass es mindestens zehn Plugins braucht, um eine Sprachaufnahme sendefähig zu bekommen. Das ist nach meiner Erfahrung völliger Quatsch und führt nur zu unnatürlichem, überproduziertem Sound. Mittlerweile ist meine Effektkette in Adobe Audition auf zwei Effekte geschrumpft: Equalizer (EQ) und Mastering-Plugin. Als erstes Plugin kommt immer der EQ zum Einsatz, denn erst nach ihm ist das Signal so, wie es weiter verarbeitet werden soll.
Equalizer
Auch an dieser Stelle habe ich mindestens ein Dutzend verschiedener Plugins versucht. Inzwischen bieten einige Hersteller EQs mit eingebauter KI an. Die Resultate mögen die Hersteller und ihre subjektives Hörempfinden überzeugen, ich fand sie meistens überscharf, hohl oder mumpfig. So bin ich irgendwann reumütig zum Audition-internen parametrischen EQ zurück gekehrt. Der einige EQ, den ich ernsthaft in Erwägung gezogen habe, ist der FastEQ von Steinberg, der bei meinem Audio-Interface dabei war. Am Ende habe ich ihn aber nur zur Analyse genutzt, wo die Schwächen in meinen Aufnahmen lag. Das geht mit dem EQ in Audition aber auch fast genau so. Hier erst einmal eine neutrale Betrachtung. Das ist der parametrische EQ, der anzeigt, welche Pegel welche Frequenzbereich haben. Ausgangspunkt waren schon die Vorschläge des FastEQ, wobei dieser aber ein Ressourcen-Fresser ist. Schon deshalb wollte ich ihn nicht weiter verwenden. Man braucht nicht in jedem Fall einen parametrischen EQ, wenn die Aufnahme im Original schon akzeptabel ist. Oft reichen dann EQs nur für vier wichtigen Bereiche Bässe, Tiefmitten, Mitten und Höhen. wenn man wenig Erfahrungen mit dem EQ hat, sind diese einfachen Plugins sogar besser und einfacher.
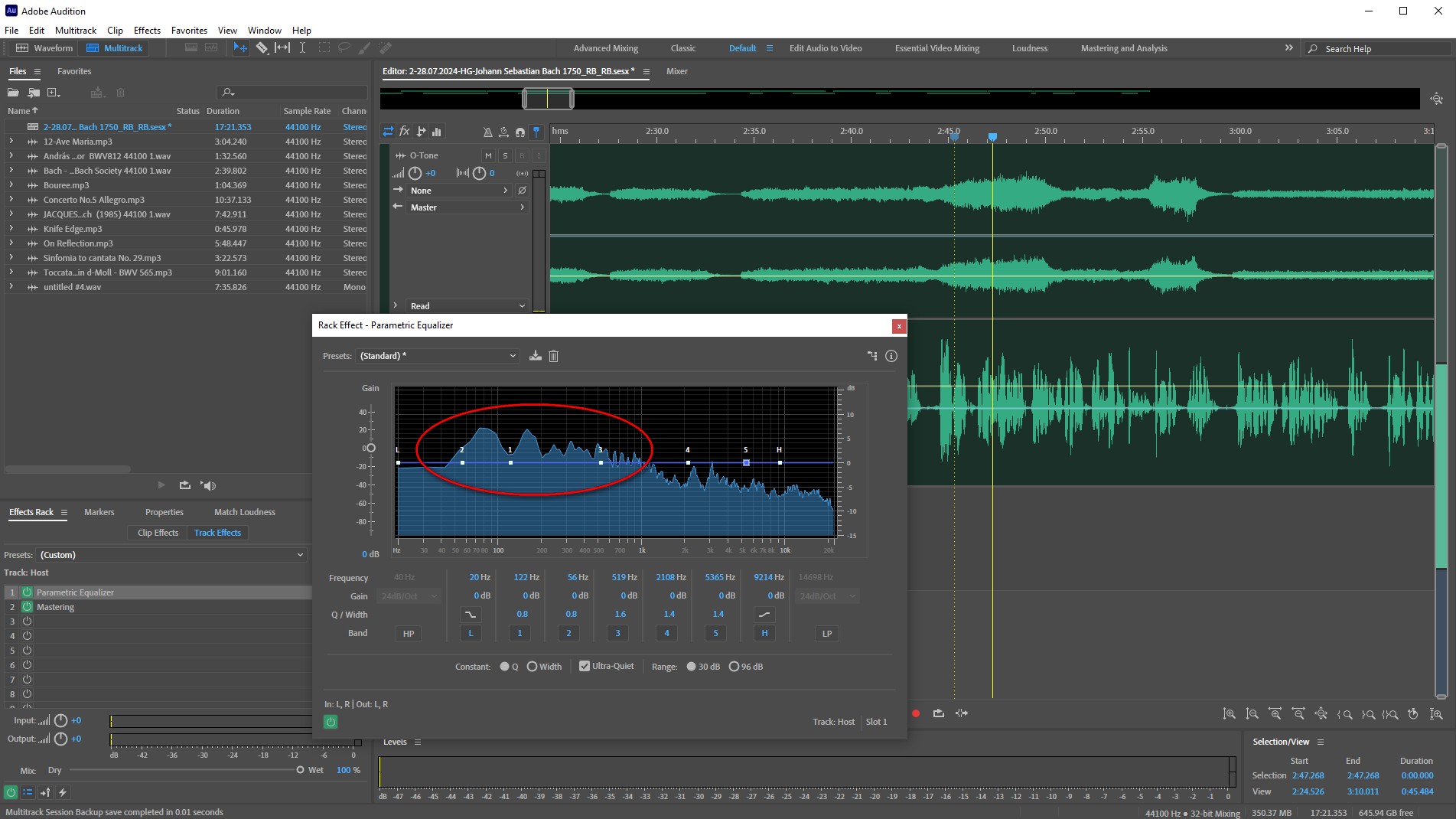 Zuerst ist der EQ auf flaches Profil gestellt. Im Hintergrund ist zu erkennen, dass mein Kleiderschrank die Bässe deutlich anhebt, genauere Analysen ergaben, dass es besonders die Bereiche 125 Hz und 180 Hz sind. Da es ein parametrischer EQ ist, streiche ich alles unterhalb von 80 Hz sehr scharf und senke auch alles unterhalb von 200 Hz deutlich ab. Nicht so, dass es jede Wärme verliert, aber so weit, dass das Dröhnen heraus genommen wird.
Zuerst ist der EQ auf flaches Profil gestellt. Im Hintergrund ist zu erkennen, dass mein Kleiderschrank die Bässe deutlich anhebt, genauere Analysen ergaben, dass es besonders die Bereiche 125 Hz und 180 Hz sind. Da es ein parametrischer EQ ist, streiche ich alles unterhalb von 80 Hz sehr scharf und senke auch alles unterhalb von 200 Hz deutlich ab. Nicht so, dass es jede Wärme verliert, aber so weit, dass das Dröhnen heraus genommen wird.
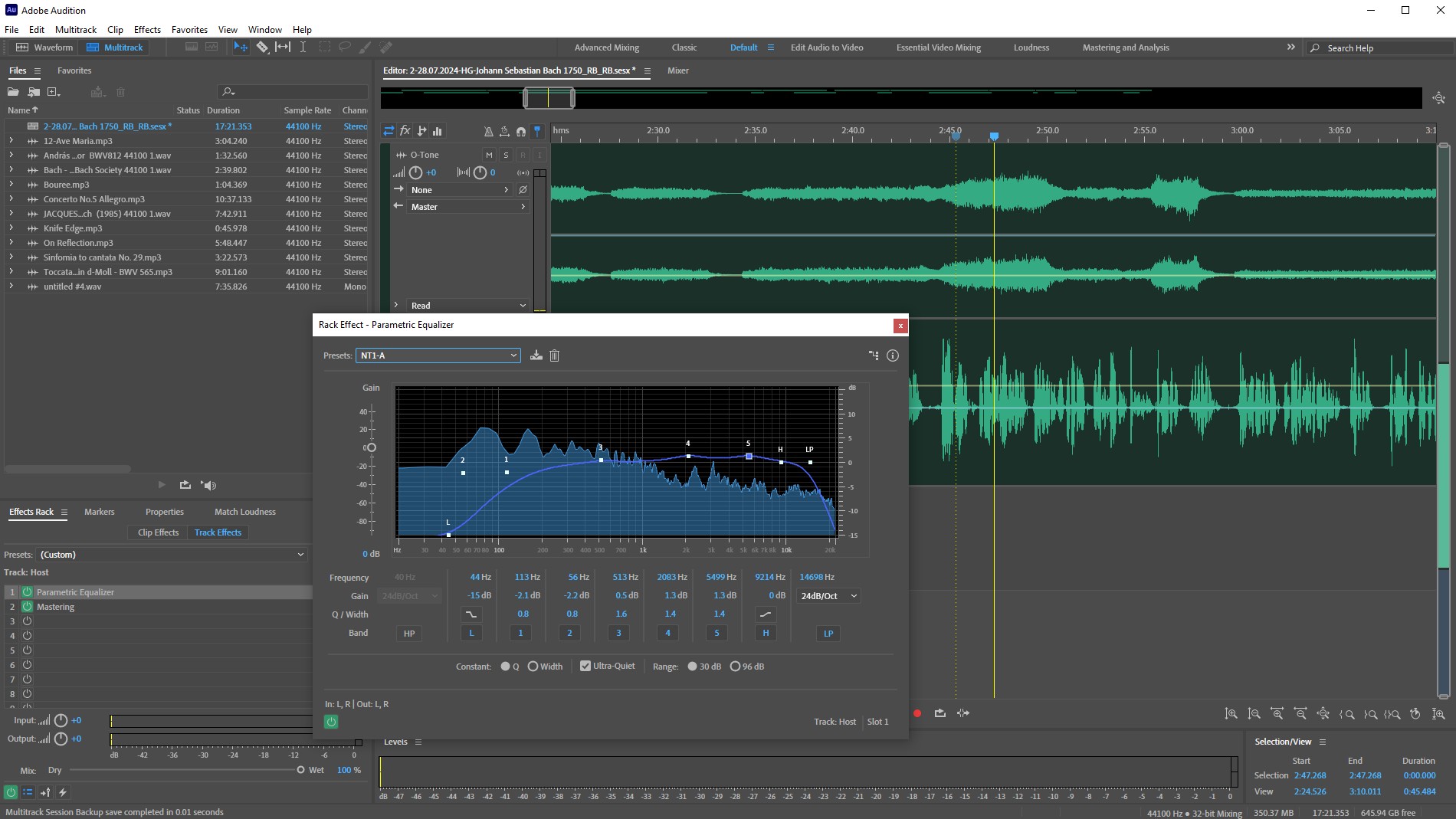 Zusätzlich, so die Erfahrung bisher, erhöht eine leichte Anhebung um 2 kHz die Verständlichkeit, etwas oberhalb von 5 kHz bring die Anhebung ein wenig mehr Glanz in die Stimme. Oberhalb von ca. 12 kHz nutze ich einen Lowpass, um Zischen und Mundgeräusche zu dämpfen. Bis ich einigermaßen zufrieden war, hat es einige Durchläufe gebraucht, denn man erwischt nicht auf Anhieb optimale Einstellungen. Nach dem EQ folgt nur noch das Mastering-Plugin, mit dem ich lediglich 15% Exciter und 20% Loudness Maximizer nutze.
Zusätzlich, so die Erfahrung bisher, erhöht eine leichte Anhebung um 2 kHz die Verständlichkeit, etwas oberhalb von 5 kHz bring die Anhebung ein wenig mehr Glanz in die Stimme. Oberhalb von ca. 12 kHz nutze ich einen Lowpass, um Zischen und Mundgeräusche zu dämpfen. Bis ich einigermaßen zufrieden war, hat es einige Durchläufe gebraucht, denn man erwischt nicht auf Anhieb optimale Einstellungen. Nach dem EQ folgt nur noch das Mastering-Plugin, mit dem ich lediglich 15% Exciter und 20% Loudness Maximizer nutze.
Dabei zeigte sich gleich ein unschöner Effekt. Das Match Loudness-Tool in Audition nutzt das originale Signal mit seinen stark überbetonten Bässen. Wenn man also O-Töne oder Musik auf zum Beispiel -16 LUFS normiert hat, ebenso die Moderation, wird diese nach dem EQ zu leise, weil ja die Bässe reduziert sind. Also musste ich im Mastering-Tool den Output um knapp 2 dB anheben, damit O-Töne und Moderation tatsächlich wieder gleiche Lautheit hatten.
Viel hilft eben nicht viel
Ein immer wieder gern gemachter Fehler ist der, mit Anhebungen zu arbeiten. Generell sollte immer mit Absenkungen gearbeitet werden. Anhebungen bringen die Pegel leicht in Übersteuerungsbereiche, die in den Anzeigen der DAW nicht angezeigt werden. Fehler Nummer Zwei ist der, dass bei Korrekturen gleich um ein paar Dezibel geändert wird, wo ein halbes oder ein Dezibel dicke reichen würden. Man muss sich bewusst sein, dass wegen der logarithmischen Bewertung 10 dB einer Verdoppelung entsprechen. Also lieber zuerst um höchstens ein dB korrigieren und probehören.
Was in einer Aufnahme zu Dröhnfrequenzen wird, hängt sehr stark vom Aufnahmeraum ab. So kann ein mumpfiger oder kistiger Klang auf Resonanzen im Bereich von 500 Hz beruhen, je nach Raum kann das aber auch im Bereich 1 kHz passieren. Deshalb ist probehören auf verschiedenen Wiedergabegeräten unverzichtbar.
Nach dem Kontrollhören ist vor dem Kontrollhören
Um dann zum finalen Stand zu kommen, ist weitreichendes Kontrollhören angesagt. Die Einstellungen des EQ mache ich zuerst mit meinem Beyerdynamic DT 990 PRO, passt es dort, wird über die KRK ROKIT5 das Ergebnis kontrolliert. Nicht nur der Klang der Moderation, sondern auch, ob Moderation und O-Töne bzw. Musik in der Lautheit wieder zusammen passen. Danach kommen die nächsten Stufen. Zwei ältere aktive Teufel-PC-Monitore in der Küche, die an einem Echo hängen, dann noch über die Stereoanlage in meinem Auto. Der Härtetest ist das Abhören über mein Samsung Galaxy TAB A7. Erst wenn überall dort Klang und Lautheit stimmen, ist die Forschung am Ende. Es empfiehlt sich, das Abhören auf genau den Geräten zu machen, auf denen man auch sonst hört. Weil man diesen Klang am besten im Ohr hat, wenn man darüber mehrere Stunden am Tag professionelles Radio hört.
Diesen Zyklus habe ich wahrlich nicht nur zwei oder drei Mal durchlaufen, sondern gefühlt ein Dutzend Mal. Die Ergebnisse werden dann als Plugin-Presets für die Plugins abgespeichert. Die Spurkonfiguration inklusive Presets dann als Template. Zumindest für die nächsten drei Wochen bin ich mit den Ergebnissen halbwegs zufrieden.
Leave a Reply
Want to join the discussion?Feel free to contribute!