
 Nur wenige Leute aus dem Amateur- oder semiprofessionellen Bereich haben die Möglichkeit, in akustisch idealen Räumen ihre Aufnahmen einzusprechen. Ich persönlich hatte mal so einen Raum, im Keller eines Einfamilienhauses, mit vielen Regalen voll Kram, die mit Vorhängen wohnlicher wurden, und einer niedrigen Decke. Nach meinem Rücksturz nach Ostwestfalen war der einzige Raum, der akustisch halbwegs akzeptabel war, mein Schlafzimmer. Zugegeben ist meine Wohnung für einen Single luxuriös groß und weitläufig. So ist das Landleben. Doch war auch das Schlafzimmer mit Bett und Teppich nicht wirklich gut, weil hallig. So kehrte ich zur Sprecherkabine für Arme zurück, meinem Kleiderschrank. Das Thema Hall hatte ich nun im Griff, handelte mir aber neue Probleme ein. Es dröhnte und klang, wegen Überdämpfung, muffig. Alles Dinge, die man mit entsprechenden EQ-Einstellungen in den Griff bekommen kann. Aber was passierte in welchen Bereichen im Frequenzverlauf? Wo dröhnte es?
Nur wenige Leute aus dem Amateur- oder semiprofessionellen Bereich haben die Möglichkeit, in akustisch idealen Räumen ihre Aufnahmen einzusprechen. Ich persönlich hatte mal so einen Raum, im Keller eines Einfamilienhauses, mit vielen Regalen voll Kram, die mit Vorhängen wohnlicher wurden, und einer niedrigen Decke. Nach meinem Rücksturz nach Ostwestfalen war der einzige Raum, der akustisch halbwegs akzeptabel war, mein Schlafzimmer. Zugegeben ist meine Wohnung für einen Single luxuriös groß und weitläufig. So ist das Landleben. Doch war auch das Schlafzimmer mit Bett und Teppich nicht wirklich gut, weil hallig. So kehrte ich zur Sprecherkabine für Arme zurück, meinem Kleiderschrank. Das Thema Hall hatte ich nun im Griff, handelte mir aber neue Probleme ein. Es dröhnte und klang, wegen Überdämpfung, muffig. Alles Dinge, die man mit entsprechenden EQ-Einstellungen in den Griff bekommen kann. Aber was passierte in welchen Bereichen im Frequenzverlauf? Wo dröhnte es?

Seit gut zehn Jahren produziere ich Beiträge für Berliner Bürgerradios, Schwerpunkte Musik und Zeitgeschichte. Da ich aber Stunden am Tag auch Radio höre, überwiegend WDR 5 und Deutschlandfunk, hatte ich immer den Sound in den Ohren, wie die Stimmen klingen sollten. Trotz vieler YouTube-Videos zu diesem Thema, mit vielen Anleitungen im Web und in Büchern, hat es seine Zeit gedauert, bis ich “meinen” Klang bekommen habe. Ein solcher Stimmklang ist immer etwas Subjektives, und wie ich als Teamleiter der Sprecher in einer ehrenamtlichen Institution weiß, hat da jeder so seine ganz eigene Vorstellung. Mein Richtwert waren aber immer die Höreindrücke, wie ich sie im professionellen Radio, und auch Podcast, eben mitgenommen habe. Diese Lernkurve, die sich über Jahre hingezogen hat, möchte ich deshalb noch einmal zusammen fassen. Auch deshalb, weil die Vorschläge und Anleitungen in Medien für mich eben nicht funktioniert haben. Fangen wir ganz vorne an.
Eine Zeit lang habe ich gerne mit dem Rode NT1-A aufgenommen. Die eine Stärke des Kondensator-Großmembraners ist das fast nicht hörbare Rauschen. Die andere ist für die Aufnahme von Gesang die Fähigkeit, auch kleinste Nuancen und Feinheiten aufzulösen, für eine Sängerin wie Adele unverzichtbar, für einen Sprecher von Texten jedoch eher nervig. Denn diese Feinsinnigkeit des NT1-A bedeutet, dass auch kleinste Unsauberkeiten wie Lippengeräusche, Schmatzen, Zungengeräusche oder nur Geräusche von der Maus in der Aufnahme landen. Das nervte mich. So holte ich wieder mein Rode Procaster aus dem Koffer, stöpselte den geliebten Triton FetHead davor und erfreute mich des warmen, angenehmen Klanges dieses mächtigen Großmembraners der dynamischen Bauweise. Keine Schmatzer mehr, keine Lippengeräusche, ein sonorer Klang, der trotzdem nicht auf Feinheiten in der Stimme und Artikulation verzichtet. Aber oh weh, da war es wieder. Wenn man sich keinen Channel Strip (also einen Mikrofon-Vorverstärker) der 2000 Euro-Klasse leisten kann oder will, ist es so sicher wie das Amen in der Kirche: das Rauschen vom Mikrofon selbst und vom Vorverstärker. Denn aufgrund physikalischer Gegebenheiten rauscht gerade ein dynamisches Mikro eben. Der Kondensator hat da prinzipbedingt die Nase vorn. Also entweder es rauschen lassen, oder … sich etwas detaillierter mit den Rauschreduzierungen in Adobe Audition auseinander setzen. Gesagt, getan. Die Zeit kostet das Erforschen, wie es geht. Hat man das getan, ist das weitgehende Ausschalten des Rauschens nur eine Sache weniger Clicks.
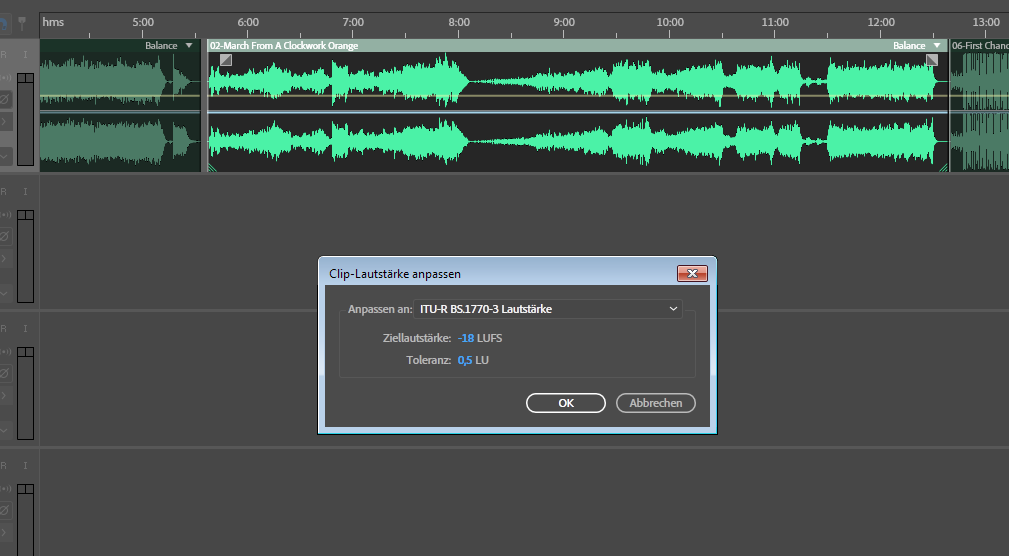 Eine wiederkehrende Situation sind Sendungen mit Musikstücken aus verschiedenen Quellen und aus verschiedenen Zeiten. Während das alte Supertramp-Album relativ leise ist, haut ein Metallica-Stück danach die Membranen aus den Lautsprechern. Mein erster Ansatz war, jeweils ein Stück über das Kontextmenü unter der rechten Maustaste auf eine bestimmte Loudness zu bringen. Das dann halt für jedes Stück. Neben der Zeit, die das Verfahren benötigte, war das auch sonst kontraproduktiv. Beim finalen Abhören der gesamten Sendung waren dann doch wieder Unterschiede in der Lautheit zu hören, weil zwar die absolute Lautheit jedes einzelnen Stücks gesetzt war, aber nicht in Relation aller beteiligten Stücke. Dazu hat Audition nämlich ein spezielles anderes Tool an Bord.
Eine wiederkehrende Situation sind Sendungen mit Musikstücken aus verschiedenen Quellen und aus verschiedenen Zeiten. Während das alte Supertramp-Album relativ leise ist, haut ein Metallica-Stück danach die Membranen aus den Lautsprechern. Mein erster Ansatz war, jeweils ein Stück über das Kontextmenü unter der rechten Maustaste auf eine bestimmte Loudness zu bringen. Das dann halt für jedes Stück. Neben der Zeit, die das Verfahren benötigte, war das auch sonst kontraproduktiv. Beim finalen Abhören der gesamten Sendung waren dann doch wieder Unterschiede in der Lautheit zu hören, weil zwar die absolute Lautheit jedes einzelnen Stücks gesetzt war, aber nicht in Relation aller beteiligten Stücke. Dazu hat Audition nämlich ein spezielles anderes Tool an Bord.
Was mich immer gestört hat, war, dass ich in der Küche über den Amazon Echo nicht meine eigene Musiksammlung hören konnte. Ich wollte eben keine Playlisten von Spotify, und auch Amazon Music war mir zu teuer und zu einseitig. Eine erste Idee, Musik von einem USB-Stick an der Fritz!-Box zu hören, scheiterte per PnP ebenfalls. So geriet das Projekt wieder in Vergessenheit. Bis mir ein älterer Raspberry in die Hände fiel.
 Das Thema treibt mich mittlerweile in den Wahnsinn. Wie mische ich eine moderierte Sendung so ab, dass Sprache und Musik subjektiv gleich laut klingen, so dass die Sprache verständlich bleibt, man aber bei der nächsten Musik nicht gleich wieder einen Sprint ans Radio einlegen muss? Bisher bin ich das Thema weitgehend experimentell angegangen, war aber mit den Ergebnissen nicht immer wirklich zufrieden. Für mich war die Reproduzierbarkeit wichtig, damit ich nicht bei jedem neuen Beitrag wieder ans Ausprobieren komme. Die Antwort war nahe liegend, aber nicht bewusst. Ich hatte die dazu sinnvollen Tools in Adobe Audition nämlich schon lange in Gebrauch, war mir aber der Tragweite ihrer Wirkung nicht wirklich bewusst.
Das Thema treibt mich mittlerweile in den Wahnsinn. Wie mische ich eine moderierte Sendung so ab, dass Sprache und Musik subjektiv gleich laut klingen, so dass die Sprache verständlich bleibt, man aber bei der nächsten Musik nicht gleich wieder einen Sprint ans Radio einlegen muss? Bisher bin ich das Thema weitgehend experimentell angegangen, war aber mit den Ergebnissen nicht immer wirklich zufrieden. Für mich war die Reproduzierbarkeit wichtig, damit ich nicht bei jedem neuen Beitrag wieder ans Ausprobieren komme. Die Antwort war nahe liegend, aber nicht bewusst. Ich hatte die dazu sinnvollen Tools in Adobe Audition nämlich schon lange in Gebrauch, war mir aber der Tragweite ihrer Wirkung nicht wirklich bewusst.
 Beim Produzieren eines Beitrages fiel mir vor einiger Zeit auf, dass der Mix in Audition noch ganz ok klang, der exportierte Mix aber deutlich schlechter. Eher grottig, die Stimme klang verwaschen und undefiniert. Verglichen mit dem Original. Am Mikro konnte es nicht liegen, der Export lief mit 192 kBit/s. Sollte also alles im grünen Bereich sein, war es aber nicht.
Beim Produzieren eines Beitrages fiel mir vor einiger Zeit auf, dass der Mix in Audition noch ganz ok klang, der exportierte Mix aber deutlich schlechter. Eher grottig, die Stimme klang verwaschen und undefiniert. Verglichen mit dem Original. Am Mikro konnte es nicht liegen, der Export lief mit 192 kBit/s. Sollte also alles im grünen Bereich sein, war es aber nicht.
Wenn man im Nachhinein darüber nachdenkt, wird klar, was da passierte. Eine Fußangel bei der Verwendung des MP3-Formates, die ich intuitiv musste, aber nicht bedachte.
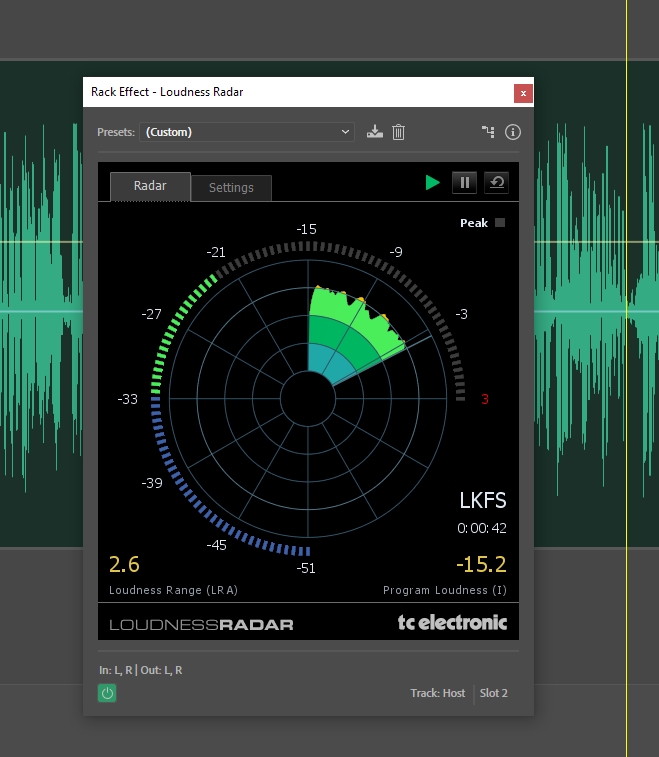 Aufnahmen nach dem maximalen Pegel auszusteuern, ist nur ein Teil der Wahrheit. In Wirklichkeit ist die Lautheit das Maß aller Dinge. Hier ein guter Artikel, der Lautheit erklärt und wie man es in der Praxis anwendet.
Aufnahmen nach dem maximalen Pegel auszusteuern, ist nur ein Teil der Wahrheit. In Wirklichkeit ist die Lautheit das Maß aller Dinge. Hier ein guter Artikel, der Lautheit erklärt und wie man es in der Praxis anwendet.
https://www.nrwision.de/mitmachen/wissen/lufs-lautheit-pegeln
Das gilt für Produktionen, die gezielt für Radio und Fernsehen gemacht werden. Geht es jedoch um Podcast oder andere Aufnahmen, die nicht über Sendeprozessoren gehen, gelten andere Regeln. In Audition ist bei der Wahl von EBU R128 als Normierungziel -23 LUFS fest eingestellt. Um andere Werte zu wählen, muss auf ITU umgestellt werden.
 Bisher kannte ich die Möglichkeit, die Lautheit (nicht den Pegel) einer Spur festzulegen, nur aus Adobe Audition. Doch hier hat Audacity nachgezogen. Seit kurzer Zeit hat Audacity unter den Effekten die Funktion zum Anpassen der Lautheit. Die Anwendung ist relativ einfach. Man wählt das Sample, das angepasst werden soll, einfach aus, ruft die Anpassung auf und gibt vor, welche Lautheit die Anpassung einstellen soll. Wie alle anderen Effekte in Audacity – im Gegensatz zu Audition – kann es Effekte nur als Bearbeitungsfunktion, nicht als dynamische Funktion handhaben. Bei der Lautheit unterscheiden sich da Audacity und Audition nicht.
Bisher kannte ich die Möglichkeit, die Lautheit (nicht den Pegel) einer Spur festzulegen, nur aus Adobe Audition. Doch hier hat Audacity nachgezogen. Seit kurzer Zeit hat Audacity unter den Effekten die Funktion zum Anpassen der Lautheit. Die Anwendung ist relativ einfach. Man wählt das Sample, das angepasst werden soll, einfach aus, ruft die Anpassung auf und gibt vor, welche Lautheit die Anpassung einstellen soll. Wie alle anderen Effekte in Audacity – im Gegensatz zu Audition – kann es Effekte nur als Bearbeitungsfunktion, nicht als dynamische Funktion handhaben. Bei der Lautheit unterscheiden sich da Audacity und Audition nicht.
 Allerdings muss man darauf achten, dass als Normalisierung die wahrgenommene Lautheit gewählt wird, was die Grundeinstellung ist. Zwar erlaubt Audacity nicht den Bezug zu den IBU-Rundfunknormen wie Audition, für den Hausgebrauch reicht es schon. Empfehlen würde ich für Podcasts die gute alte -16 LUFS-Vorgabe von Apple, die -14 LUFS bei Amazon halte ich für zu laut. Wenn man regelmäßig Jingles verwendet, sollte man diese einmal so normieren und danach erneut abspeichern. Verkürzt den Workflow gerade bei großen Sample erheblich.
Allerdings muss man darauf achten, dass als Normalisierung die wahrgenommene Lautheit gewählt wird, was die Grundeinstellung ist. Zwar erlaubt Audacity nicht den Bezug zu den IBU-Rundfunknormen wie Audition, für den Hausgebrauch reicht es schon. Empfehlen würde ich für Podcasts die gute alte -16 LUFS-Vorgabe von Apple, die -14 LUFS bei Amazon halte ich für zu laut. Wenn man regelmäßig Jingles verwendet, sollte man diese einmal so normieren und danach erneut abspeichern. Verkürzt den Workflow gerade bei großen Sample erheblich.
Nicht zum automatischen Anpassen, aber zum Ausmessen der Lautheit bietet sich das Youlead Loudness Meter an.
 Ein Kritikpunkt an Audacity, im Vergleich zu anderen Programmen wie Adobe Audition oder Steinberg Cubase, ist der, dass die mitgelieferten Effekte leider nur statische sind. Man kann einen Effekt an einer Spur nur nutzen, wenn man das Sample auswählt und den Effekt anwendet. War es nicht der gewünschte Effektpegel oder die angezielte Wirkung, muss man mit STRG-Z zurück, andere Parameter für den Effekt einstellen und wieder anwenden. Diese Anwendung der Effekte liegt an der Art, wie Audacity entwickelt wurde, nämlich für gleich mehrere Betriebssysteme. Linux, Windows und weitere. Und die handhaben dynamische Effekte jeweils sehr unterschiedlich. So genannte dynamische Effekte, bei denen man im laufenden Betrieb Effektparameter ändern kann und gleichzeitig mithören, muss man nachträglich einbringen. Dieses geht mit den VST-Plugins, Software-Module, deren Schnittstelle die Firma Steinberg schon vor langer Zeit definiert hat. Ein weiterer Vorteil dieser Plugins ist der, dass man zum Beispiel Compressoren oder Equalizer nach dem Anwendungsziel aussucht. Weil ein Compressor für ein Schlagzeug anders verwendet wird als für Sprache oder Gesang. Seltsamerweise haben sich unzählige Hersteller an diese Schnittstelle für Plugins gehalten, weshalb sie heute ein Quasistandard ist. Doch ist die Nutzung der VST-Plugins in Audacity nicht ganz trivial. In Cubase oder Audition geht das einfacher. Aber es ist auch keine Raketenwissenschaft.
Ein Kritikpunkt an Audacity, im Vergleich zu anderen Programmen wie Adobe Audition oder Steinberg Cubase, ist der, dass die mitgelieferten Effekte leider nur statische sind. Man kann einen Effekt an einer Spur nur nutzen, wenn man das Sample auswählt und den Effekt anwendet. War es nicht der gewünschte Effektpegel oder die angezielte Wirkung, muss man mit STRG-Z zurück, andere Parameter für den Effekt einstellen und wieder anwenden. Diese Anwendung der Effekte liegt an der Art, wie Audacity entwickelt wurde, nämlich für gleich mehrere Betriebssysteme. Linux, Windows und weitere. Und die handhaben dynamische Effekte jeweils sehr unterschiedlich. So genannte dynamische Effekte, bei denen man im laufenden Betrieb Effektparameter ändern kann und gleichzeitig mithören, muss man nachträglich einbringen. Dieses geht mit den VST-Plugins, Software-Module, deren Schnittstelle die Firma Steinberg schon vor langer Zeit definiert hat. Ein weiterer Vorteil dieser Plugins ist der, dass man zum Beispiel Compressoren oder Equalizer nach dem Anwendungsziel aussucht. Weil ein Compressor für ein Schlagzeug anders verwendet wird als für Sprache oder Gesang. Seltsamerweise haben sich unzählige Hersteller an diese Schnittstelle für Plugins gehalten, weshalb sie heute ein Quasistandard ist. Doch ist die Nutzung der VST-Plugins in Audacity nicht ganz trivial. In Cubase oder Audition geht das einfacher. Aber es ist auch keine Raketenwissenschaft.
Winterabende bieten sich gerne für Basteleien an. Deshalb habe ich noch einmal einige meiner Mikrofone versammelt, um ihre unterschiedlichen Sounds und Raumqualitäten zu vergleichen. Aufgenommen habe ich natürlich die Rohdaten, danach wurden sie mit iZotope Nektar 4 Elements in Adobe Audition noch mit künstlicher Intelligenz bearbeitet. Bei den dynamischen Mikros kam vor dem Interface noch ein FEThead zum Einsatz, um 20 dB mehr Ausgangspannung zu holen.
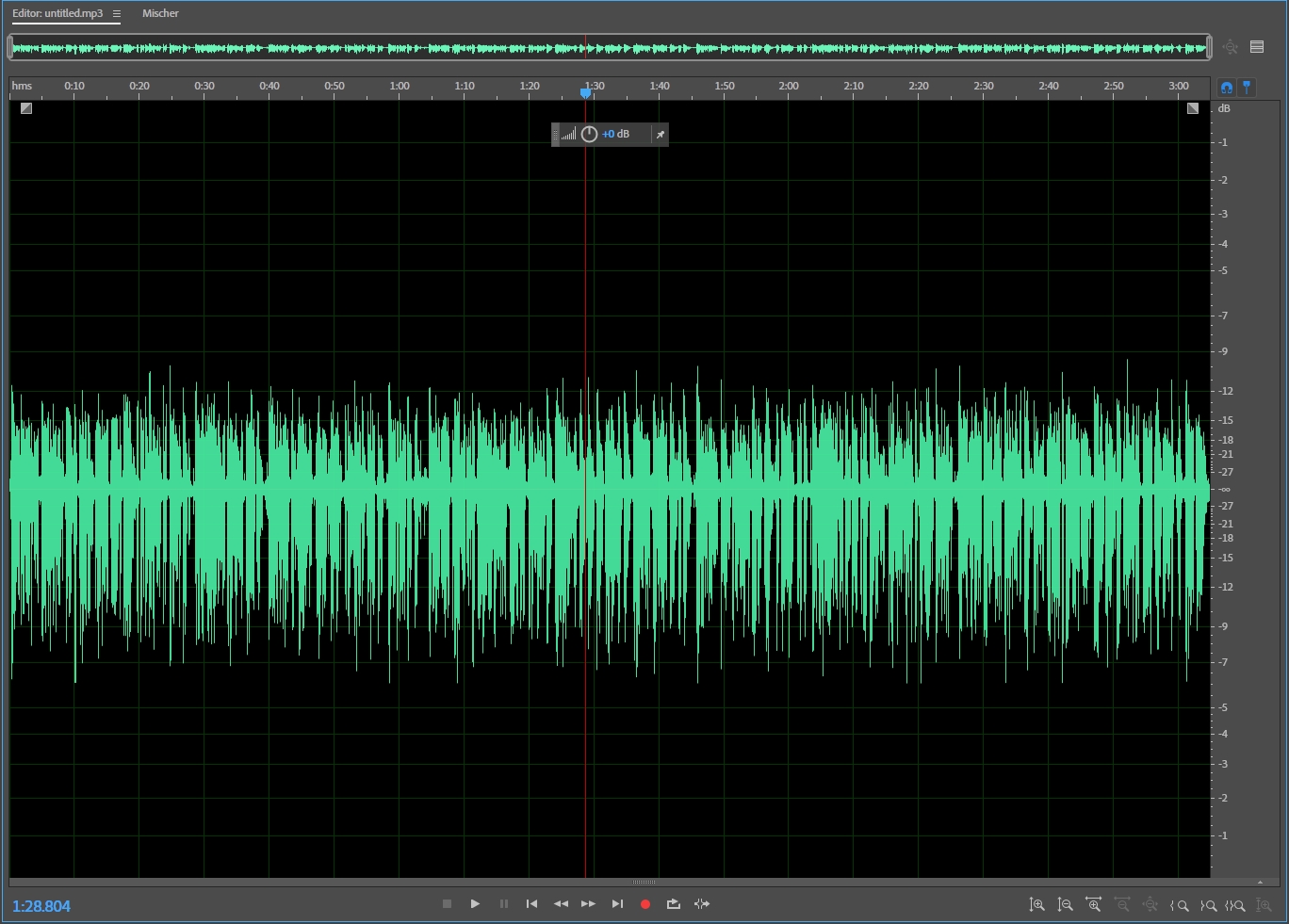 Es war mir schon mal aufgefallen, ich hatte es jedoch ignoriert: Aufnahmen von Moderationen waren irgendwie schief, die Signale oberhalb der Nulllinie waren deutlich schwächer als die unterhalb. Ich schob das auf die Elektronik und ließ es gut sein, denn akustisch war ja alles in Ordnung. Bis ich eine neue Runde einlegte, den eingesprochenen Text für die Aussendung möglichst gut einzupegeln und Spitzen durch Schmatzer, Klicker oder Atmer zu nivellieren. Das geht ganz gut mit dem Hard Limiter in Adobe Audition, werde ich noch einmal separat beschreiben. Der Limiter brachte aber nur teilweise Besserung, denn ihm war es ja egal, ob die Signale positiv oder negativ waren. Das Ergebnis war ein schön nivelliertes Signal im positiven Bereich, aber der negative sah aus wie mit der Schere abrasiert. Was tun? Und warum ist das Signal so schräg? Wenn man es weiß, ist es plausibel.
Es war mir schon mal aufgefallen, ich hatte es jedoch ignoriert: Aufnahmen von Moderationen waren irgendwie schief, die Signale oberhalb der Nulllinie waren deutlich schwächer als die unterhalb. Ich schob das auf die Elektronik und ließ es gut sein, denn akustisch war ja alles in Ordnung. Bis ich eine neue Runde einlegte, den eingesprochenen Text für die Aussendung möglichst gut einzupegeln und Spitzen durch Schmatzer, Klicker oder Atmer zu nivellieren. Das geht ganz gut mit dem Hard Limiter in Adobe Audition, werde ich noch einmal separat beschreiben. Der Limiter brachte aber nur teilweise Besserung, denn ihm war es ja egal, ob die Signale positiv oder negativ waren. Das Ergebnis war ein schön nivelliertes Signal im positiven Bereich, aber der negative sah aus wie mit der Schere abrasiert. Was tun? Und warum ist das Signal so schräg? Wenn man es weiß, ist es plausibel.