
Seit mindestens 15 Jahren höre ich Podcasts, von 2013 bis 2017 schon deshalb, weil ich am Wochenende zwischen Paderborn und Celle gependelt bin. Fahrzeit pro Wochenende mindestens drei Stunden. Damals nutzte ich Winamp als Podcatcher, kopierte die Podcasts auf einen USB-Stick und hörte die Beiträge dann im Auto. Seit 2021 bin ich zwar im Ruhestand, höre nicht mehr ganz so viele Podcasts, nutzte immer noch Winamp, musste dann aber die Podcasts per FTP auf mein Tablet kopieren. Um sie dann über Mittag zu hören. Winamp hat leider mit den letzten Updates gerade bei Podcasts immer mehr Macken, vergisst die Abos oder lädt neue Beiträge nicht herunter. Der Nachfolger WACUP ist eher noch mieser, was Podcatching betrifft. Es musste eine andere Lösung her. Ohne viel Kopieren und manuelle Arbeit.
Posts

 Nur wenige Leute aus dem Amateur- oder semiprofessionellen Bereich haben die Möglichkeit, in akustisch idealen Räumen ihre Aufnahmen einzusprechen. Ich persönlich hatte mal so einen Raum, im Keller eines Einfamilienhauses, mit vielen Regalen voll Kram, die mit Vorhängen wohnlicher wurden, und einer niedrigen Decke. Nach meinem Rücksturz nach Ostwestfalen war der einzige Raum, der akustisch halbwegs akzeptabel war, mein Schlafzimmer. Zugegeben ist meine Wohnung für einen Single luxuriös groß und weitläufig. So ist das Landleben. Doch war auch das Schlafzimmer mit Bett und Teppich nicht wirklich gut, weil hallig. So kehrte ich zur Sprecherkabine für Arme zurück, meinem Kleiderschrank. Das Thema Hall hatte ich nun im Griff, handelte mir aber neue Probleme ein. Es dröhnte und klang, wegen Überdämpfung, muffig. Alles Dinge, die man mit entsprechenden EQ-Einstellungen in den Griff bekommen kann. Aber was passierte in welchen Bereichen im Frequenzverlauf? Wo dröhnte es?
Nur wenige Leute aus dem Amateur- oder semiprofessionellen Bereich haben die Möglichkeit, in akustisch idealen Räumen ihre Aufnahmen einzusprechen. Ich persönlich hatte mal so einen Raum, im Keller eines Einfamilienhauses, mit vielen Regalen voll Kram, die mit Vorhängen wohnlicher wurden, und einer niedrigen Decke. Nach meinem Rücksturz nach Ostwestfalen war der einzige Raum, der akustisch halbwegs akzeptabel war, mein Schlafzimmer. Zugegeben ist meine Wohnung für einen Single luxuriös groß und weitläufig. So ist das Landleben. Doch war auch das Schlafzimmer mit Bett und Teppich nicht wirklich gut, weil hallig. So kehrte ich zur Sprecherkabine für Arme zurück, meinem Kleiderschrank. Das Thema Hall hatte ich nun im Griff, handelte mir aber neue Probleme ein. Es dröhnte und klang, wegen Überdämpfung, muffig. Alles Dinge, die man mit entsprechenden EQ-Einstellungen in den Griff bekommen kann. Aber was passierte in welchen Bereichen im Frequenzverlauf? Wo dröhnte es?
Eine Zeit lang habe ich gerne mit dem Rode NT1-A aufgenommen. Die eine Stärke des Kondensator-Großmembraners ist das fast nicht hörbare Rauschen. Die andere ist für die Aufnahme von Gesang die Fähigkeit, auch kleinste Nuancen und Feinheiten aufzulösen, für eine Sängerin wie Adele unverzichtbar, für einen Sprecher von Texten jedoch eher nervig. Denn diese Feinsinnigkeit des NT1-A bedeutet, dass auch kleinste Unsauberkeiten wie Lippengeräusche, Schmatzen, Zungengeräusche oder nur Geräusche von der Maus in der Aufnahme landen. Das nervte mich. So holte ich wieder mein Rode Procaster aus dem Koffer, stöpselte den geliebten Triton FetHead davor und erfreute mich des warmen, angenehmen Klanges dieses mächtigen Großmembraners der dynamischen Bauweise. Keine Schmatzer mehr, keine Lippengeräusche, ein sonorer Klang, der trotzdem nicht auf Feinheiten in der Stimme und Artikulation verzichtet. Aber oh weh, da war es wieder. Wenn man sich keinen Channel Strip (also einen Mikrofon-Vorverstärker) der 2000 Euro-Klasse leisten kann oder will, ist es so sicher wie das Amen in der Kirche: das Rauschen vom Mikrofon selbst und vom Vorverstärker. Denn aufgrund physikalischer Gegebenheiten rauscht gerade ein dynamisches Mikro eben. Der Kondensator hat da prinzipbedingt die Nase vorn. Also entweder es rauschen lassen, oder … sich etwas detaillierter mit den Rauschreduzierungen in Adobe Audition auseinander setzen. Gesagt, getan. Die Zeit kostet das Erforschen, wie es geht. Hat man das getan, ist das weitgehende Ausschalten des Rauschens nur eine Sache weniger Clicks.
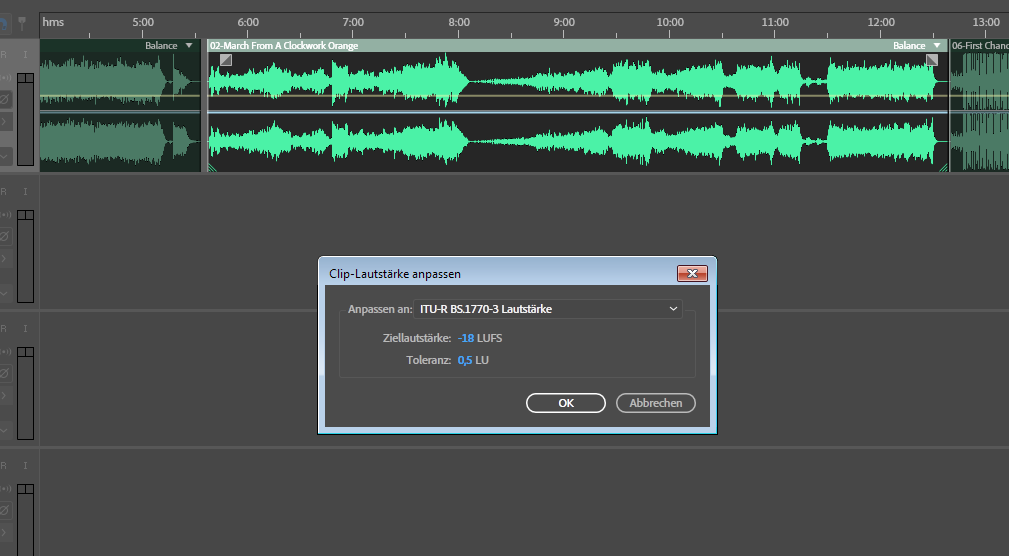 Eine wiederkehrende Situation sind Sendungen mit Musikstücken aus verschiedenen Quellen und aus verschiedenen Zeiten. Während das alte Supertramp-Album relativ leise ist, haut ein Metallica-Stück danach die Membranen aus den Lautsprechern. Mein erster Ansatz war, jeweils ein Stück über das Kontextmenü unter der rechten Maustaste auf eine bestimmte Loudness zu bringen. Das dann halt für jedes Stück. Neben der Zeit, die das Verfahren benötigte, war das auch sonst kontraproduktiv. Beim finalen Abhören der gesamten Sendung waren dann doch wieder Unterschiede in der Lautheit zu hören, weil zwar die absolute Lautheit jedes einzelnen Stücks gesetzt war, aber nicht in Relation aller beteiligten Stücke. Dazu hat Audition nämlich ein spezielles anderes Tool an Bord.
Eine wiederkehrende Situation sind Sendungen mit Musikstücken aus verschiedenen Quellen und aus verschiedenen Zeiten. Während das alte Supertramp-Album relativ leise ist, haut ein Metallica-Stück danach die Membranen aus den Lautsprechern. Mein erster Ansatz war, jeweils ein Stück über das Kontextmenü unter der rechten Maustaste auf eine bestimmte Loudness zu bringen. Das dann halt für jedes Stück. Neben der Zeit, die das Verfahren benötigte, war das auch sonst kontraproduktiv. Beim finalen Abhören der gesamten Sendung waren dann doch wieder Unterschiede in der Lautheit zu hören, weil zwar die absolute Lautheit jedes einzelnen Stücks gesetzt war, aber nicht in Relation aller beteiligten Stücke. Dazu hat Audition nämlich ein spezielles anderes Tool an Bord.
Was mich immer gestört hat, war, dass ich in der Küche über den Amazon Echo nicht meine eigene Musiksammlung hören konnte. Ich wollte eben keine Playlisten von Spotify, und auch Amazon Music war mir zu teuer und zu einseitig. Eine erste Idee, Musik von einem USB-Stick an der Fritz!-Box zu hören, scheiterte per PnP ebenfalls. So geriet das Projekt wieder in Vergessenheit. Bis mir ein älterer Raspberry in die Hände fiel.
 Das Thema treibt mich mittlerweile in den Wahnsinn. Wie mische ich eine moderierte Sendung so ab, dass Sprache und Musik subjektiv gleich laut klingen, so dass die Sprache verständlich bleibt, man aber bei der nächsten Musik nicht gleich wieder einen Sprint ans Radio einlegen muss? Bisher bin ich das Thema weitgehend experimentell angegangen, war aber mit den Ergebnissen nicht immer wirklich zufrieden. Für mich war die Reproduzierbarkeit wichtig, damit ich nicht bei jedem neuen Beitrag wieder ans Ausprobieren komme. Die Antwort war nahe liegend, aber nicht bewusst. Ich hatte die dazu sinnvollen Tools in Adobe Audition nämlich schon lange in Gebrauch, war mir aber der Tragweite ihrer Wirkung nicht wirklich bewusst.
Das Thema treibt mich mittlerweile in den Wahnsinn. Wie mische ich eine moderierte Sendung so ab, dass Sprache und Musik subjektiv gleich laut klingen, so dass die Sprache verständlich bleibt, man aber bei der nächsten Musik nicht gleich wieder einen Sprint ans Radio einlegen muss? Bisher bin ich das Thema weitgehend experimentell angegangen, war aber mit den Ergebnissen nicht immer wirklich zufrieden. Für mich war die Reproduzierbarkeit wichtig, damit ich nicht bei jedem neuen Beitrag wieder ans Ausprobieren komme. Die Antwort war nahe liegend, aber nicht bewusst. Ich hatte die dazu sinnvollen Tools in Adobe Audition nämlich schon lange in Gebrauch, war mir aber der Tragweite ihrer Wirkung nicht wirklich bewusst.
Winterabende bieten sich gerne für Basteleien an. Deshalb habe ich noch einmal einige meiner Mikrofone versammelt, um ihre unterschiedlichen Sounds und Raumqualitäten zu vergleichen. Aufgenommen habe ich natürlich die Rohdaten, danach wurden sie mit iZotope Nektar 4 Elements in Adobe Audition noch mit künstlicher Intelligenz bearbeitet. Bei den dynamischen Mikros kam vor dem Interface noch ein FEThead zum Einsatz, um 20 dB mehr Ausgangspannung zu holen.
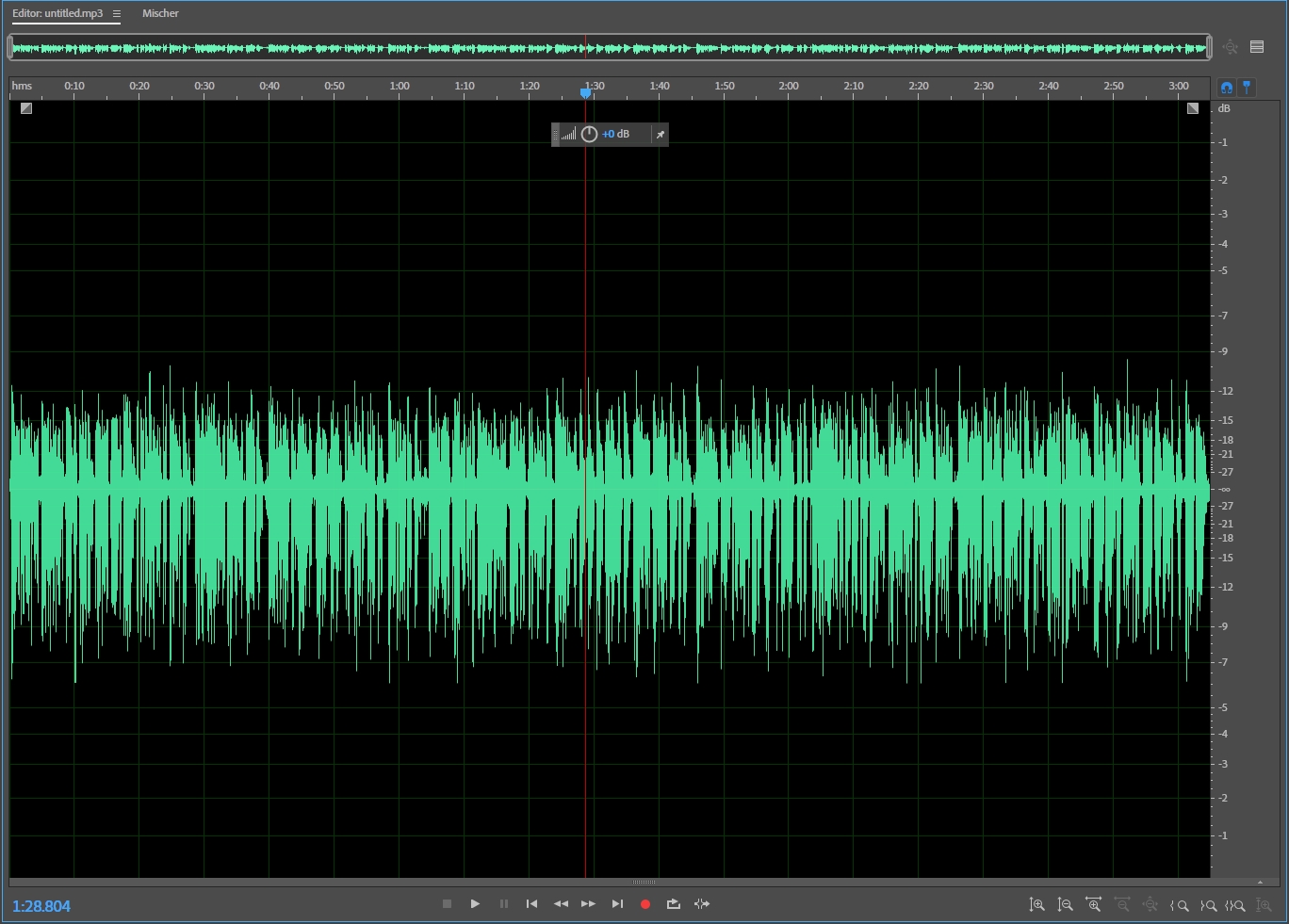 Es war mir schon mal aufgefallen, ich hatte es jedoch ignoriert: Aufnahmen von Moderationen waren irgendwie schief, die Signale oberhalb der Nulllinie waren deutlich schwächer als die unterhalb. Ich schob das auf die Elektronik und ließ es gut sein, denn akustisch war ja alles in Ordnung. Bis ich eine neue Runde einlegte, den eingesprochenen Text für die Aussendung möglichst gut einzupegeln und Spitzen durch Schmatzer, Klicker oder Atmer zu nivellieren. Das geht ganz gut mit dem Hard Limiter in Adobe Audition, werde ich noch einmal separat beschreiben. Der Limiter brachte aber nur teilweise Besserung, denn ihm war es ja egal, ob die Signale positiv oder negativ waren. Das Ergebnis war ein schön nivelliertes Signal im positiven Bereich, aber der negative sah aus wie mit der Schere abrasiert. Was tun? Und warum ist das Signal so schräg? Wenn man es weiß, ist es plausibel.
Es war mir schon mal aufgefallen, ich hatte es jedoch ignoriert: Aufnahmen von Moderationen waren irgendwie schief, die Signale oberhalb der Nulllinie waren deutlich schwächer als die unterhalb. Ich schob das auf die Elektronik und ließ es gut sein, denn akustisch war ja alles in Ordnung. Bis ich eine neue Runde einlegte, den eingesprochenen Text für die Aussendung möglichst gut einzupegeln und Spitzen durch Schmatzer, Klicker oder Atmer zu nivellieren. Das geht ganz gut mit dem Hard Limiter in Adobe Audition, werde ich noch einmal separat beschreiben. Der Limiter brachte aber nur teilweise Besserung, denn ihm war es ja egal, ob die Signale positiv oder negativ waren. Das Ergebnis war ein schön nivelliertes Signal im positiven Bereich, aber der negative sah aus wie mit der Schere abrasiert. Was tun? Und warum ist das Signal so schräg? Wenn man es weiß, ist es plausibel.