In der Tat ist es bei längeren und komplexen Themen und Texten sinnvoll, den Beitrag vorzuschreiben. Sinnvoll ist es nicht, ihn so zu schreiben wie sonstigen Text, also schön und optisch ansprechend, und mit optimalem Schrifteindruck. Denn das Ziel bei diesem Text ist es, den Text möglichst fehlerfrei und fließend lesen zu können. Der Text soll das Sprechen unterstützen. Dafür gibt es ein paar Stellschrauben, die werden in Büchern auch genannt. An einigen Stellen bin ich erst durch einen einzelnen amerikanischen Kollegen zurecht gekommen. Das Ganze in Listenform.
Seitenformat A4 ist gut, aber mit deutlichen Seitenrändern, z. B. drei Zentimetern. Der Weg der Augen wird dadurch kürzer gehalten und der Zeilensprung fällt leichter.
Als Schriftart eignet sind am besten eine Serifen-Schrift. Sie leitet wegen der Serifen die Augen besser, die Orientierung fällt leichter. Ich verwende Dark Courier. Sie ist angefettet, aber noch nicht fett und hat deutliche Serifen. Die Schriftart muss nicht proportional sein, wie gerne behauptet wird.
Zeilenabstand doppelt, damit der Zeilensprung deutlich ausfällt. Hilft ebenso der Orientierung.
Im gleichen Sinne: regelmäßige Absätze. Mindestens drei pro Seite.
Meine persönliche Erkenntnis schlechthin: im Gegensatz zu den Vorschlägen in Büchern verwende ich keine besonders große Schriftgröße, sondern eine, die ich aus Sichtabstand vor dem Aufnahmepult noch gerade eben gut entziffern kann. Ich war verblüfft, dass das tatsächlich besser funktioniert als große Schrift, weil dadurch, der Wahrnehmung entsprechend, nur die gesamten Wörter erfasst werden, keine Einzelbuchstaben. Man liest flüssiger.
Bei einem Layout wie im Screenshot macht eine Seite ca. anderthalb Minuten gesprochenen Text.
Kleine und größere Helferlein
Ein Tisch-Bücherständer leistet gute Dienste beim Einsprechen im Sitzen. Mit etwas Geschick bekommt man sogar drei Seiten platziert. Mit einem solchen Ständer, ein Notenständer oder ein Klemmbrett hilft auch, hat man kein Papier in der Hand und raschelt nicht herum. Jedenfalls bleibt in meinen Händen kein Papier still. YMMV. Blattwechsel schneidet man später heraus oder nimmt in Etappen auf.
Generell bin ich vom Einsprechen im Sitzen abgegangen. Obwohl es etwas mystisch erscheint, es macht einen großen Unterschied, ob man beim Sprechen sitzt oder steht. Die Atmung verändert sich, im Stehen hat man die Hände frei, kann etwas agieren, die Sprache ist freier. Nimmt man vorwiegend oder nur im eigenen Wohnraum ein, ist ein Orchesterpult optimal. Auf diesem steht das Manuskript, an den oberen Rand kommt eine Klemme für das Mikro. An dieser Klemme findet dann noch gleich der Pop-Schutz Halt. Beide Klemmen stammen von K&M, die große Version hat noch den Vorteil, dass sie fast beliebig positioniert werden kann. Erhältlich beim Musikhändler des Vertrauens oder bei Thomann. Hier die einfache und hier die große Klemme.
https://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.png00Rainer Böttchershttps://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.pngRainer Böttchers2024-02-25 17:42:072024-02-25 17:42:07Schreiben fürs Sprechen – Die Dritte
Einer der größten Fehler, die ich am Anfang gemacht habe: mit der Tür ins Haus zu fallen. Direkt in medias res, sofort die volle Breitseite. Erst Stefan Wachtel hat mir mit seinen Büchern bessere Methoden an die Hand gegeben. Neben der Wortwahl, dem Sprachstil und den Formulierungen spielt auch die Struktur von Beiträgen eine wesentliche Rolle. Was mir am Anfang nicht wirklich bewusst war.
Einleiten, Abholen, Wecken
Stellen wir uns eine reale Situation vor. Der Hörer und die Hörerin (ich verwende am jetzt den Begriff Hörer für beide Geschlechter) sitzen beim Abendessen, spülen das Geschirr oder machen gerade sonst etwas. Nun kommt unser Beitrag im Radio. Es wäre zuviel verlangt, dass sofort alle Aufmerksamkeit uns gehört, unserem Beitrag, unserer “Message”. Wir müssen die beiden erst einmal abholen, müssen sie gedanklich an den Lautsprecher holen, Interesse wecken. Die Nachrichten haben es da besser, sie wollen gehört werden, ihnen gilt – in der Regel – eh das volle Interesse. Uns nicht.
Daher Wachtels Regel Nummer Eins: situieren, situieren, situieren. Wir müssen dem Hörer klar machen, dass hier etwas für ihn Interessantes kommt. Und sei es nur etwas Unterhaltendes. Dazu gehört das Situieren, das Einleiten in den Beitrag. Das kann eine Anekdote sein, eine Geschichte oder etwas Verwandtes aus dem Alltag. Der Kniff dabei ist, möglichst viele Menschen anzusprechen, Spezialisierungen sind nicht hilfreich. Mit dieser Einleitung fangen wir den Hörer ein.
Beispiel: das Historische Ereignis in der Zeitzone des Ohrfunks.
Sagen Sie mal, haben Sie eigentlich Punkte in Flensburg? (Pause) Und wie viele? (Pause) Na, das geht ja noch. Punkte in Flensburg, den Begriff kennt wohl jeder Autofahrer. Heute nämlich, am so-und-so-vielten wurde im Kraftfahrtbundesamt in Flensburg das Allgemeine Verkehrregister eingerichtet …
Persönlich werden, persönlich bleiben
Von Sendungen abgesehen, in denen es um Fakten geht, interessiert den Hörer nicht, was er eh schon weiß. Wenn ich über die Beatles spreche, brauche ich dem Hörer nicht zu erzählen, dass sie aus Liverpool kamen. Oder dass John Lennon der Bandgründer war, weil das mein Hörer wohl eh weiß. Eher sollte ich die Beatles aus meiner Sicht schildern, meine Erinnerungen, meine Positionen. Natürlich soll den Hörer das Thema interessieren, aber es sucht neue Aspekte, neue Sichten. Und die kann ich nur aus meiner eigenen Sicht angehen. Es sei denn, es sind Informationen, die wahrscheinlich eher unbekannt sind. Aber der wichtige Punkt ist, dass es meine Sicht, meine Perspektive ist. Und nicht die, die er auch in Wikipedia nachlesen kann.
Die Grenzen des Radios
Im Vergleich zu Fernsehen und Internet unterliegt das Radio einer großen Beschränkung. Wir können nur Töne übermitteln. Was bedeutet, dass wir Bilder nur in den Köpfen unserer Hörer realisieren können, indem wir sie rufen. Was man ausgiebig tun sollte, denn nur Bilder können Stimmungen und Situationen transportieren. Das kann sein, dass wir in der Anmoderation das Wetter draußen, die Atmosphäre im Studio oder die Fahrt zum Sender schildert. Oder dass man eben betont bildhafte Sprache einsetzt. Nicht allein abstrakte Begriffe und Fakten, sondern Bilder. Bilder erhöhen nicht nur die Verständlichkeit und vermitteln Atmosphären, sie machen Texte leichter fassbar. Statt 50%: jeder Zweite. Statt 120.000 Menschen: eine ganze Kleinstadt wie Paderborn. Statt 400 Milliarden Euro: fast soviel wie der Bundeshaushalt.
Struktur wahren
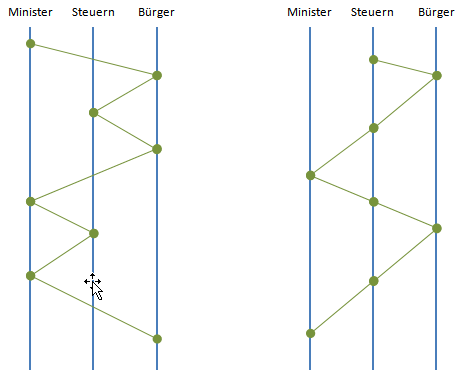
Jeder Beitrag braucht eine Struktur, der der Hörer folgen kann. Der Begriff des narrativen Stils trifft diese Forderung sehr gut, es geht nicht um das Aufzählen von Fakten, Daten und Ereignissen, die Elemente müssen an einem Zeit- oder Themenstrahl ausgerichtet sein. Nichts ist schlimmer, als zwischen den Punkten der Geschichte hin und her zu springen. Der Hörer wird dem nur schwerlich folgen können. Das kann man am besten in einer Grafik darstellen, zum Beispiel anhand eines Beitrages über den Finanzminister, die Steuern und den Bürgern.
Der Themenfluss des Beitrages sollte so linear wie möglich sein, damit der Hörer dem Verlauf folgen kann. Der linke Verlauf tut das eher weniger, er springt zwischen den Fokuspunkten hin und her, was den Hörer verwirrt. Der rechte Verlauf ist besser in der Lage, einen logischen und verfolgbaren Verlauf zu erzeugen. Die Geschichte mag dem Redakteur klipp und klar sein, der Hörer hat diesen Hintergrund nicht, er hat sich nicht mit den Inhalten so beschäftigt.
Narrativ bedeutet auch, dass der Beitrag in sich schlüssig ist, in den Fakten wie in den zeitlichen Zusammenhängen. Ständig zwischen Vergangenheit, Gegenwart und Zukunft zu wechseln, mag interessant aussehen, verständlich ist es nicht.
Ein weiterer Stolperstein ist der, dass man nicht alles Vorwissen beim Hörer voraus setzen kann. Sei es Politik, Wissenschaft oder Fremdwörter und Fachbegriffe. Häufungen von fremden Wörtern veranlassen den Hörer zum Abschalten. Manchmal reicht schon ein einziger Begriff.
Struktur des Beitrages ist ebenso wichtig wie Sprache und Formulierungen. Optimal wird es, wenn man das Thema in eine Geschichte verpacken kann, die mit den berühmten “anregenden Zusätzen” versehen ist. Das, was den Beitrag interessant und für den Hörer lebensnah macht.
Den Hörer nicht allein zurück lassen
Genau so wichtig wie eine Situierung ist der Abschluss. Die ideale Form ist, im Abspann wieder den Faden des Anfangs aufzunehmen, sei es mit einem Fazit, mit einer Erkenntnis oder einem Witz. Die meiste Aufmerksamkeit beim Beitrag gilt dem Ende, dem Beginn und erst danach dem Inneren der Geschichte. Mit der Situierung hole ich den Hörer hinein, mit dem Abspann lasse ich ihn wieder los und teile ihm das auch mit. Es ist nicht günstig, wie bei den Hard News den harten Strich zu ziehen, Ende der Nachricht, die nächste bitte.
Stattdessen den Beitrag abschließen, ihn abrunden und dabei etwas zurück lassen, an das sich der Hörer vielleicht als Erstes erinnern wird, wenn er sich den Beitrag wieder ins Gedächtnis ruft. Situierung und Abschluss klammern die ganze Geschichte. So wie “Es war einmal …” und “… lebten sie glücklich für den Rest ihres Lebens.” ein Märchen klammert. Diese Struktur der Märchen ist nicht zufällig, sie hilft dem Hörer in der Orientierung und er weiß, dass der Beitrag nun zu Ende ist.
Im Grunde sind es wenige und einfache Regeln und Leitlinien, die einen Beitrag verträglich und griffig machen. Wer in das Thema Struktur und Ablauf im Radio noch tiefer einsteigen möchte, kann ich die Bücher von Stefan Wachtel nur wärmstens ans Herz legen.
https://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.png00Rainer Böttchershttps://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.pngRainer Böttchers2024-02-25 17:37:222024-02-25 17:37:22Schreiben fürs Sprechen – Die Zweite
Als ich mit dem Radiomachen anfing, war mir das Konzept für die ersten Beiträge weitgehend klar. Die Technik war auch kein Thema. Fehlten noch die Texte. Ich ging den sicheren Weg, wie ich heute weiß, wie fast jeder. Schrieb die Texte vor, las sie ab, mischte Text, Musik, Opener und Jingles, fertig war der erste Beitrag. Es folgten weitere, heute produziere ich Beiträge für den Ohrfunk, ein gutes Jahr Lernkurve liegt hinter mir. So viel zur Vorgeschichte. Wenn ich mir heute ältere Beiträge von mir anhöre, ist das eine der effektivsten Lernkurven überhaupt. Wenn man vom allgemeinen Journalismus ins Radio gerät, schreibt man so, wie man eine Nachricht oder einen Bericht schreibt. Hat man Glück, sind Rezensionen noch im Gedächtnis und es wird etwas lockerer, farbiger, freier. Aber meistens hat man Pech. Und so klingt der Text dann auch, eben mehr vorgelesen als moderiert, steif, wenig unterhaltend. Das ist aber gerade das Zeil einer Moderation, zu unterhalten, beim Hörer Interesse zu wecken.
Von diesem Sprech- und damit Schreibstil weg zu kommen, hat mich gut ein Jahr gekostet. Und ich muss zugeben, dass ich ohne die hilfreichen Werke auf der Bücherliste im Abschnitt “Radio/Podcast” noch länger herum gedoktert hätte. Mittlerweile steigt meine Zufriedenheit und es geht lockerer. Zwar bin ich von Tommi Bongartz und Manni Breuckmann noch Äonen entfernt, hier dann doch ein paar Anmerkungen aus meiner Lernkurve. Den Inhalt der vielen Bücher kann ich nicht einmal streifen, aber es sind die grundlegenden Erkenntnisse, die mir das Leben heute leichter machen. Und ich beziehe mich nur auf Moderationen, Features oder Kommentare, nicht auf Hard News.
Schreibsprache und Sprechsprache
Dass vorgeschriebene Texte so leblos und starr klingen, liegt an der ganz anderen Satzbildung und Wortwahl, je nachdem, ob wir sprechen oder schreiben. Beobachtet man bewusst, wie man spricht und vergleicht das mit Geschriebenem, sind die Unterschiede nicht offensichtlich. Doch es gibt sie:
Sprechsprache verwendet viele Binde- und Füllwörter wie “auch”, “aber”, “wohl” oder “etwas”. In der Schreibsprache sind diese Wörter in der Regel ausgemerzt.
Bei normaler Alltagssprache kommen Substantivierungen und Formsprache praktisch nicht vor. Alltagssprache ist gerade aus.
Ebenso Fachwörter oder komplizierte Begriffe, es sei denn, sie müssen sein.
Sprechsprache zieht Aktiv vor, Passiv wird nur dort verwendet, wo es tatsächlich um einen passiven Vorgang geht.
Obwohl grammatisch nicht ganz korrekt, benutzen wir in der Sprechsprache überwiegend Gegenwart und Perfekt. Obwohl die Vergangenheit benutzt werden sollte.
Sätze sind eher kürzer und kompakter. Lange und kurze Sätze wechseln oft.
Sprechsprache im Alltag, und Moderationen sind Alltag, ist reduzierter als Schreibsprache. Das, was und wie wir sprechen, würden wir im Normalfall so nicht zu Papier bringen. Sprechsprache ist weniger linear, weniger komplex und entsteht ja erst nach einem unbewussten Vordenken. Schreiben wir dagegen einen Text, so feilen wir schon in der Erstausgabe, noch vor dem Redigieren. Gesprochenes dagegen enthält grundsätzlich mehr Redundanz, überflüssige Wörter, mehr Nebensätze, mehr Füllstoff. Ein weiterer, meistens nicht auffälliger Bestandteil von Sprechsprache, sind Lücken, Ungenauigkeiten und Pausen. Faktor Nummer Drei ist die Sprachmelodie, im Alltag variieren wir die Stimme in viel größeren Bereichen als beim Vorlesen eines Textes. Da geht die Stimme schon mal weit mehr nach oben als beim Lesen. Denn beim Sprechen sind weit mehr Emotionen beteiligt. Aber gerade das ist in der Moderation das Ziel, auch emotional zu wirken.
Vom Sprechen zum Schreiben
Es ist am Anfang ziemlich schwer, von der Schreibsprache wegzukommen und in eine Sprechsprache umzuschalten. Eine größere Hilfe als oft ein Stapel Bücher ist die Fähigkeit, sich selbst für eine Zeit bewusst zu beobachten. Wenn ich spreche, wie sehen meine Sätze aus? Welche Wörter verwende ich oft und wo, in welchem Zusammenhang? Wie “baue” ist Sätze beim Sprechen? Daraus lassen sich einige Regeln ableiten, auf die ich achte, nicht als Korsett, sondern eher als roter Faden.
Füllwörter nutzen. Der Text wird redundanter, lockerer, aufgelockert. Wiederholungen sind kein Fehler, in der Sprechsprache sind sie nicht zu vermeiden.
Wechsel zwischen kurzen und langen Sätzen. Längere Sätze mit einem oder wenigen Nebensätzen. Ein Sinnschrtt pro Satz.
Einfügungen, kurze Sinnwechsel lockern den Text auf, auch im Alltag schweifen wir mal kurz ab.
Benutzen von Wörtern, die nicht unbedingt zur Schriftsprache gehören (Trumm statt Schiff, Kollege statt Mann, Blatt statt Zeitung, Schmöker statt Buch etc.).
Der Text steht nicht für sich alleine und klingt nicht für sich alleine. Mimik, Gestik und Ausdruck hört man tatsächlich. Sie verändern Muskeln im Körper und beeinflussen den Klang der Sprache.
Denkpausen, kurze Stops oder Suchpausen sind Teil der Sprechsprache.
Je nach Format, Umgebung, Platzierung und Medium kann es sogar passen, Begriffe oder Formulierungen aus der Umgangssprache oder aus dem Dialekt einzuflechten.
Am Ende erfordert das Schreiben von Texten fürs Sprechen etwas Übung darin, in Gedanken zu sprechen und genau das aufzuschreiben. Was zuerst ungewohnt ist. Aus Schule und Ausbildung sind wir eingenordet, statisch zu schreiben, haben die Regeln für gute Aufsätze oder Berichte verinnerlicht. Sich den Freiheitsgrad zurück zu gewinnen, zu schreiben wie uns der Schnabel gewachsen ist, ist Arbeit. Und erfordert genau so Übung und Lernkurven wie das Gegenteil, nämlich exaktes und ausgefeiltes Schreiben. Einige Trainer nutzen Hilfen. Eine davon ist, sich jemanden vorzustellen, oder tatsächlich ein Bild vor sich zu hängen, zu dem man spricht. Also, Angie, was ich Dir schon lange mal erzählen wollte …
https://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.png00Rainer Böttchershttps://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.pngRainer Böttchers2024-02-25 17:35:142024-02-25 17:35:14Schreiben fürs Sprechen – Die Erste
Vor schon längerer Zeit hatte ich mich mit dem Thema »Schreiben fürs Sprechen« beschäftigt. Nach reichlichem Quellenstudium, zahllosen Beiträgen im Netz und mit so einigen Büchern. Während man in diesem Fall, dass man seine Texte für einen Beitrag schreibt, die Sache noch weitgehend in der Hand hat, sieht die Sache ganz anders aus, wenn man fremde Texte einsprechen soll. Die sind nämlich in fast allen Fällen eben nicht fürs Sprechen gedacht. Es ist dann nicht die Ausnahme, dass solche Texte kaum ordentlich zu sprechen sind. Weil sie eben als Pressemeldungen oder sonstige Zwecke verfasst wurden. Wie nun an diese Herausforderungen heran gehen? Damit bin ich nun seit einiger Zeit konfrontiert, allmählich schält sich jedoch auch für diese Fälle eine Art Workflow heraus.
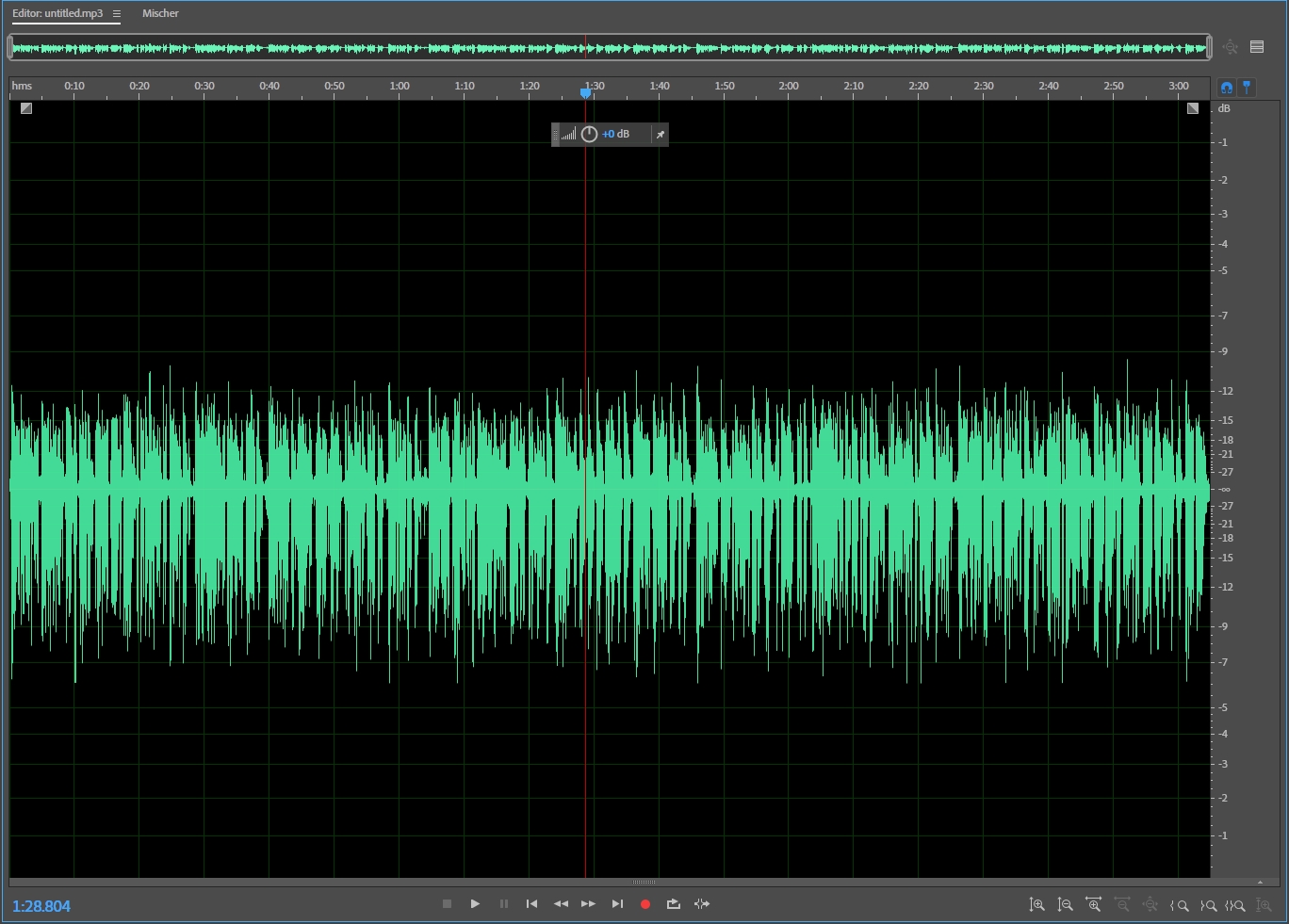
Es war mir schon mal aufgefallen, ich hatte es jedoch ignoriert: Aufnahmen von Moderationen waren irgendwie schief, die Signale oberhalb der Nulllinie waren deutlich schwächer als die unterhalb. Ich schob das auf die Elektronik und ließ es gut sein, denn akustisch war ja alles in Ordnung. Bis ich eine neue Runde einlegte, den eingesprochenen Text für die Aussendung möglichst gut einzupegeln und Spitzen durch Schmatzer, Klicker oder Atmer zu nivellieren. Das geht ganz gut mit dem Hard Limiter in Adobe Audition, werde ich noch einmal separat beschreiben. Der Limiter brachte aber nur teilweise Besserung, denn ihm war es ja egal, ob die Signale positiv oder negativ waren. Das Ergebnis war ein schön nivelliertes Signal im positiven Bereich, aber der negative sah aus wie mit der Schere abrasiert. Was tun? Und warum ist das Signal so schräg? Wenn man es weiß, ist es plausibel.
https://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.png00Rainer Böttchershttps://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.pngRainer Böttchers2024-02-25 17:14:112024-02-25 17:46:24Das Ganze noch mit Adobe Audition
Vor einiger Zeit habe ich ein paar Demo-Videos für das Sicher-Stark-Team produziert (wo ich Leiter der SprechInnen-Gruppe bin). Vielleicht noch anders nützlich.
https://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.png00Rainer Böttchershttps://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.pngRainer Böttchers2024-02-25 17:10:572024-02-25 17:10:57Podcasts mit Oceanaudio und Audacity
Der vorherige Teil über Podcasts ging in der Hauptsache auf die technischen Aspekte ein. Und wie so übliche Lernkurven verlaufen, gibt es nach der realen Produktion so einiger Sendungen neue Erfahrungen. Diese bei mir gesammelt aus der Produktion von Podcasts über Musik. Nicht verschweigen sollte ich, dass mein ursprünglicher Berufswunsch einmal Toningenieur war, ich 40 Jahre Elektronik-Erfahrung verbuchen kann und eine Lehre als Rundfunk- und Fernsehtechniker in den goldenen Siebzigern so manche technische Frage erst gar nicht aufkommen lässt.
Noch einmal Technik
The Writer’s Pit
Der aktuelle Setup sieht zur Zeit so aus:
Das »Studio« befindet sich im Keller, der mit Dämmmaterial und Vorhängen auf eine trockene Akustik getrimmt wurde. Es ist tatsächlich mein ruhigster Raum, von einem Abwasserrohr abgesehen, aber ab ca. 20:00 Uhr herrscht Ruhe. Optimale Zeiten sind Fußball-Finale oder -Halbfinale, da hat man bald 45 Minuten Bewegungsarmut im Haus. Auch der Tisch ist mit einem dicken Handtuch bespannt, gegen Reflektionen.
Vom Mikro geht es in ein Behringer-XENYX 1204-Pult, das sich tatsächlich als Produkt mit den besten Resultaten bei geringen Kosten gezeigt hat. Selbst das teurere Alesis-Pult rauschte mehr und hatte zu wenig Routingmöglichkeiten zum Verteilen der Signale aus Mikro oder Recorder auf Kopfhörer, zum Abhören und Mithören. Und genug Kanäle und Busse kann man selbst beim Podcast nie haben. Nicht alles, was billig ist, ist schlecht. Eine Kurzeinführung zu Mischpulten findet sich in Just Chords.
Diverse Mikrofone von Thomann aus dem unteren und mittleren Preissegment kamen zum Einsatz. Der Nachteil billiger Kondensator-Mikros ist, dass sie rauschen. Und das nicht zu knapp. Das einzige Mikro, das nicht rauschte, war mein gutes, altes, dynamisches Shure SM57, aber das taugte nicht für Sprachaufnahmen. So musste am Ende doch investiert werden. Eine neue Lernkurve begann.
Wenn man sucht, kann man leicht in die falsche Richtung suchen. So kommt man dann zu einem Mikro für Gesang und Instrumente statt zu einem Sprecher-Mikrofon. Das brachte das Røde NT1-A ins Haus. Das Røde NT1-A ist absolut ruhig, kein Rauschen und ein unglaublich guter Klang. Dafür bekommt man zu diesem Preis auch eine sehr gute Spinne und einen stabilen Pop-Filter dazu. Der Nachteil des sehr fein auflösenden NT1-A ist der, dass das Mikro empfindlich genug ist, damit selbst ein grummelnder Magen deutlich hörbar auf die Aufnahme kommt. Und noch dazu jeder Schmatzer, jedes Lippenlecken, selbst nur Speichelgeräusche beim Sprechen. Schöner Klang, feinste Auflösung, aber für das Einsprechen eines Podcastes schon zu empfindlich. Für Gesang sicher optimal. Für Einsprechen von Texten weniger.
Daher ist die ideale Lösung ein Mikro, das genau für den Sprecheinsatz im Rundfunk gemacht wurde: das Røde Procaster ist ein dynamisches Mikrophon mit idealen Eigenschaften. Mehr dazu unten im Video. Aber damit kam ein neues Problem auf den Tisch. Das Procaster produziert nur, da dynamisch und passiv, einen sehr geringen Ausgangspegel. So gering, dass der Kanal des Mischpultes auf maximale Verstärkung aufgezogen werden muss. Das Ergebnis ist das gleiche wie mit den billigen Konsensatormikros: Rauschen. Als Abhilfe dient nun ein Mikro-Vorverstärker, der ART MP Tube. Auch der muss ziemlich aufgezogen werden, aber es bleibt im akzeptablen Bereich. Das Finden des “richtigen” Mikros war die längste Lernkurve.
Dynamische Mikrofone haben einen Nahbesprechungsefekt. Je näher am Mikro man spricht, desto stärker werden die Bässe hervor gehoben. Kann ein gewollter Effekt sein, in der Regel ist das nicht so. Es erfordert einiges Experimentieren, die richtige Entfernung zum Mikro zu finden, in der es nicht dröhnt, die Stimme jedoch klar und deutlich herüber kommt. Der Tipp aus dem Video unten war Gold wert.
Brummschleifen können grausam sein, sie entstehen aus der Verkettung von Masse-Leitungen, die dann in der Luft herum streunende Netzspannungssignale einfangen und ins Pult leiten. Vom Behringer-Pult läuft daher das Signal in einen Behringer UCA202 Audio-USB-Adapter. Der klingt besser, als sein Preis vermuten lässt. Und er trennt galvanisch Pult und PC, auf dem mit Goldwave aufgenommen wird. Der PC ist ein Netbook, das keinen Lüfter hat und die Aufnahmen nicht stört. Die Performance reicht allemal, und der Bildschirm für das Aufnehmen auch.
Ist noch kein Netbook oder leiser PC vorhanden, kommen eher ein Recorder wie der Zoom H2n oder vergleichbare Geräte in Frage. Selbst das billige Olympus Diktiergerät hat für 70 Euro eine erstaunlich gute Audioqualität über den externen Mikrofoneingang. Es muss als nicht immer Highend-Equipment sein, mit etwas Probieren geht es auch billig und gut. Weil oft in den billigen Geräten aus Produktionsgründen die gleichen Bauteile stecken wie in teuren.
Texte sind komplett vorgeschrieben, das ist Geschmackssache. Wenn man Texte schreiben kann, die wie laufende Sprache klingen, und diese auch möglichst frei und natürlich sprechen kann, ist es die sicherste Lösung. Die Aufnahme der Texte in einem Rutsch oder in getrennten Abschnitten landet auf einem USB-Stick, das Schneiden erfolgt später im Wohnzimmer an einem i5-PC und mit einem 22-Zoll-Schirm geht das doch komfortabler.
Produktion
Die Produktion ist nicht nur das Zusammenfügen der einzelnen Elemente. Ziel soll ja auch sein, die gesamte Aufnahme gut klingen zu lassen. Dazu gehört, dass die Gesamtaufnahme nicht nur mit Studiomonitoren oder im Auto passt, sondern mit möglichst allem, was man als Wiedergabemöglichkeiten hat. Das betrifft das Verhältnis der Lautstärken von Sprache und Musik, oder anderen Elementen, als auch die Frequenzgänge. Gerade am Anfang sollte man seine Produktionen über verschiedene Anlagen probehören, bevorzugt die, die für den Hörer zum Einsatz kommen wie PC-Lautsprecher oder Stereoanlage. Es nervt, wenn man die Stimme kaum versteht, aber die Musik brüllt, oder umgekehrt. Daher die eher aufwändige Bearbeitung bei der Produktion. Dröhnen oder spitze Höhen sind nervige Komponenten, die gezielt bearbeitet werden müssen. Was manche Podcasts so nervig oder langweilig macht, sind nicht immer nur die Inhalte. Unebener Schnitt und schlechter Klang sind noch viel schlimmer.
Wer glaubt, er lädt sich ein paar VSTi-Plugins herunter und macht das alles mal ebenso, liegt falsch und degradiert alle Toningenieure. Ich habe jedenfalls reichlich Stunden gebraucht, zu klanglich und schnitttechnisch akzeptablen Ergebnissen zu kommen.
Schnitt
n-Track7 mit Broadcaster-Plugin
Bei der Aufnahme habe ich einen Zettel zur Hand, auf dem ich mir die Zeiten der aufgenommenen Abschnitte notiere. Geht ein Teil daneben, wird die Zeit durchgestrichen und neu aufgenommen. So braucht man beim Schnitt nicht zu viel zu suchen.
Die Textelemente werden mit Goldwave, oder Steinberg WaveLab, aus der Gesamtaufnahme in einzelne Abschnitte als .wav-Dateien isoliert und auf maximale Aussteuerung gezogen. Bei Goldwave heißt das Maximize volume. Über die Textaufnahmen läuft jetzt ein Compressor, der den Pegel gleichmäßiger macht, Goldwave hat einen passenden Preset Effects|Dynamics & Compressor|Reduce peaks, dann wird der Pegel noch einmal auf maximale Aussteuerung gebracht und hat eine überschaubare Dynamik.
Die Musik wird ebenso mit Goldwave aus MP3 ins WAV-Format konvertiert und erfährt ein Heraufsetzen auf 95% des maximalen Pegels. Hier ist etwas Vorsicht geboten, denn gerade neuere Aufnahmen sind oft so hochkomprimiert, dass sie in der Lautstärke mit alten Aufnahmen schwer in gleichen Höreindruck zu bringen sind.
Für das Zusammenfügen von Musik, Text, Opener und Closer kommt nun n-Track zum Einsatz. n-Track ist keine Freeware, aber kostet nur ein Taschengeld. Dafür sind die Möglichkeiten und Funktionen, einschließlich der Oberfläche, kostenlosen Programmen wie Audacity weit überlegen. Alleine die vollständige VSTi-Integration ist ein Segen. Die einzelnen Elemente wie Text und Musik werden nun in zwei bis drei Spuren platziert und passend mit Envelopes – Hüllkurven für Laustärken – zum eventuellen Ein- und Ausblenden belegt. Im Screenshot von n-Track oben sieht man das genauer. Das alles ist keine Rocket Science, aber auch nicht trivial. Bevor der erste Podcast entsteht, mit dem man zufrieden ist, können viele Stunden mit Kämpfen vergehen. Weil etwas nicht funktioniert, nicht klingt oder beides.
Das Ergebnis landet aus n-Track als WAV-Datei auf der Platte und wird mit RazorLAME in das MP3-Format gebracht. Sender haben gerne 320 kBit/s, 44.1 kHz und Constant Bitrate. Fertig. Wären da nicht die Tricks, auf die man nicht sofort kommt.
Plugins
Plugins sind Programme, die nicht eigenständig laufen, sondern in Tools wie Audacity oder n-Track eingebunden werden. Sie filtern oder verändern die Signale einzelner Tracks oder des Gesamtsignals mit Hall, Compression oder vielen anderen Effekten. Logisch kann man sie sich wie ein Effektgerät vorstellen, das zwischen Instrument und Verstärker eingeschleift wird.
Die Plugins legt man am besten in ein Verzeichnis seiner Wahl, z. B. C:\\Programme\VSTi und sammelt dort in Unterverzeichnissen seine Lieblinge. Vergessen darf man nicht, dem Multitracker n-Track oder Audacity mitzuteilen, wo denn die Plugins stehen. Und es sollte einen Rescan für die VSTi-Plugins geben, die dann in der Effektliste auftauchen.
Diese Plugins sind das A und O der Produktion. Ob man nun ein bisschen Hall braucht, oder einen Equalizer oder Limiter, die Plugins erledigen alle diese Aufgaben. Doch nicht alle Plugins sind gleich, manche Freeware-Versionen können grottenschlecht sein. Eines der besten Hall-Plugins ist Ambience. Das kostet nur ein paar Euros, aber dafür bekommt man dann auch fast professionelle Tools. Freie VSTi-Plugins sucht man über Google, oder auch direkt bei Cakewalk.
Tipps und Tricks
Auf Nahbesprechungseffekte, Rauschen und solche Fußangeln bin ich schon oben eingegangen. Fängt man mit der Podcast-Produktion an, erwartet man nicht die vielen Schwierigkeiten, die auftauchen. Rauschende Mikros und Pulte, Brummschleifen, Geräusche aus der Umgebung sind Dinge, die man in den Griff bekommen muss. Doch ein paar Dinge weiß man erst, wenn man auf die Nase gefallen ist …
Voice Processor
Wer schon mal einen bekannten Moderator aus dem Radio live gehört hat, merkt den Unterschied. Aus dem Studio klingt es satter und breiter. Was daran liegt, dass im Studio immer ein Voice Processor mitläuft, der dem eigentlichen Sprachsignal zusätzliche Obertöne, Formanten, hinzu fügt. Dadurch bekommt die Stimme mehr Klang. Ein solches Gerät ist für den privaten Produzenten kaum erschwinglich. Aber es gibt sogar kostenfreie Alternativen als VSTi-Plugins. Eines der besten ist JB Broadcast, ein Voice Processor, der leider nicht mehr verfügbar ist, weil der Entwickler neue Plugins geschrieben hat. Daher hier mal als Download abgelegt. Weiterhin verwendbar sind After und VocEq sowie Rescue und RescueAE. Die letzten Plugins sind noch verfügbar und werden als Mastering Tools in den Track der Moderation als Effekt eingefügt. Ein wenig Probieren und Spielen muss sein, um für seine Stimme das Beste herauszuholen. Bei JB Broadcast nutze ich, mit tiefer Stimme und mittlerer Lautstärke, den Preset Normal, schalte die Pegelregelung (AGC) aus und setze den Postgain auf -1 dB.
Pegel, Pegel und noch einmal Pegel
Nicht einfach ist es, die Lautstärke zwischen Moderation und Musik auf ein kompatibles Maß zu bekommen. Ein Weg ist der, alle Bestandteile auf 100% zu normaliseren, bei der Moderation zwei Mal, einmal vor und einmal nach der Compression (Goldwave hat für diese Schritte schon alles eingebaut). Danach wird in n-Track die Moderation um ein bis anderthalb dB im Pegel zurück genommen, die Musik um ein halbes dB. Radiosender und Studios haben dafür andere Vorgaben, für den Bereich Rockmusik hat sich ein Pegelverhältnis Moderation/Musik von nahezu 1:1 bewährt. Bei Klassik sollte ebenfalls die Musik auf 100% normalisiert werden, jedoch die Moderation um vier bis sechs dB zurück genommen werden, da die Pegelweiten bei klassischer Musik anders sind. Probieren, probehören, justieren. Bei mir stellte es sich als optimal heraus, die Moderation auf maximalen Pegel zu ziehen und die Musik um -4 dB abzusenken. Das sind die obeigen 95%. Am Anfang eine unvermeidbare Geschichte, später weiß man, wie man die Pegelverhältnisse einstellen und erhören kann, denn sie hängen natürlich auch von der eigenen Stimme ab. Ein Hoch auf ein Paar zuverlässige Studio-Monitore am PC, damit bekommt man schon einen ganz zuverlässigen Eindruck, wie es beim Hörer später inetwa ankommt.
Immer böse: Latenz
Obwohl man denkt, dass Latenz, die Verzögerung zwischen Abschicken des Signals in die Audioschnittstelle und Ankunft am analogen Ausgang, bei Podcasts keine Rolle spielen sollte, liegt man falsch. Nicht für den Podcast später, sondern für das Arbeiten mit der Mischsoftware. Latenzen sind nämlich nicht konstant, sondern hängen von der Belegung der Puffer im Betriebssystem ab. Obwohl man beim Abmischen noch korrigiert, spielt die unterschiedliche Speichernutzung mit mehreren Spuren eine Rolle. Einfache Lösung: entweder nach einem ASIO-Treiber für die Audioschnittstelle suchen, oder einen unversellen ASIO-Treiber installieren, ASIO4All. Ist kostenlos erhältlich.
Was nichts kostet …
Wie professionell oder eben auch nicht es wird, hängt von den Investitionen ab. Sparen am Mikro ist die schlimmste Sünde, die man sich leisten kann. Doch die einen oder anderen zwanzig Euro für vernünftige Software zu verwenden, macht sich im Arbeiten und auch in den Ergebnissen bemerkbar. n-Track mag auf den ersten Blick verwirrend aussehen, aber es erlaubt mehr an Funktionen als eben Audacity. Auch mit den Softwareversionen von Steinberg, die bei Produkten wie Soundkarten oder USB-Audio-Schnittstellen dabei sind, kann man schon besser arbeiten als mit Audacity. Man sollte sich den Gedanken sparen, es würden mal eben etwas Software und Hardware zusammen gesteckt und fertig ist der Podcast. Dieses Verfahren zieht entsprechende Ergebnisse nach sich.
Text, Text und noch mal Text
Letzter Punkt sind die Moderationstexte selbst. Der Vorteil beim kompletten Ausformulieren ist, dass die Fehlerrate beim Einsprechen deutlich sinkt. Der Nachteil ist, dass es oft gerade am Anfang wie Vorlesen aus der Zeitung klingt. Auch das geht nicht bei den ersten drei Aufnahmen, man muss es lernen und üben, sich an den Klang der eigenen Stimme gewöhnen und auch Selbstkritik üben. Füllwörter, die man im schriftlichen Journalismus meidet, flapsige Begriffe und Alltagssprache sind in der Audio-Moderation unverzichtbar. Trotzdem darauf achten, dass in den Füllwörtern eine Varianz vorhanden und zu hören ist. Ein Podcast ist keine Nachrichtensendung, er soll unterhalten. Unterhaltung hat eine andere Sprache als Nachrichten. Auf der anderen Seite stark subjektive Wertungen und Urteile vermeiden. Die gehören auch nicht in einen Podcast, selbst in einen über Musik nicht.
Eine wenigstens etwas hilfreiche Maßnahme gegen zu leierigen Text ist Sprachtraining. Wer jedoch für den einen oder anderen Podcast nicht gleich eine Sprecherausbildung machen will, kann mit Büchern wie diesem anfangen. Keine Garantie, aber schon Tipps und wenige Regeln können helfen.
Zielgruppen-gerecht denken!
Und immer daran denken: der Köder muss dem Fisch schmecken, nicht dem Angler.
https://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.png00Rainer Böttchershttps://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.pngRainer Böttchers2022-02-26 20:13:272024-02-26 20:14:53Podcast Stufe Zwei
Podcasts überall, nicht nur in Blogs und anderen Web-Quellen, auch viele Sendungen der Rundfunkanstalten, welch altmodisches Wort, sind als Podcasts verfügbar. Gut, was so viele scheinbar können, sollte einfach sein. Ist es auch, wenn man die Technik im Griff hat und sich über Inhalte klar ist. Hier also eine Anleitung zum Erstellen von Podcasts, was man braucht und was nicht.
Beginnen wir mit der Technik, meistens das größte Hindernis, trotz der Annahme, dass heute selbst ein Grundschüler einen PC konfigurieren könnte.
Hardware
Vorausgesetzt, der PC ist komplett vorhanden, brauchen wir minimal noch:
Am einfachsten ein an den PC direkt über USB anschließbares Mikro, und einen Kopfhörer. Ein sehr gutes Mikro für den direkten Anschluss ist das Rode NT-USB Mini, ein Kondensator-Mikro, an das man einen Kopfhörer direkt anschließen kann.
Oder ein Headset, Kopfhörer und Mikro in einem, beides für den direkten Anschluss an die Soundkarte des PCs. Quelle wie zuvor. Empfehlungen: LOGITECH PC860 (ca. 10 Euro) bis zu SENNHEISER PC151 (ca. 70 Euro). Sennheiser baut sehr ordentliche Headsets, auch im Bereich von 30 Euro. Bitte einen Hörer mit zwei Seiten nehmen, die einseitigen treiben einen schnell in den akustischen Wahnsinn.
Das wäre die Hardware-mäßige Minimal-Ausstattung. Möchte man es semiprofessionell machen, sähe die Liste etwas anders aus:
Am besten ein Kondensator-Mikrofon wie das Rode NT1-A, oder etwas Vergleichbares. Die Firma Thomann liefert mit ihrer eigenen T-Bone-Serie ganz brauchbare Mikros zu zivilen Preisen.
Ein Audio-Interface wie die Scarlett-Produkte von Focusrite oder das UR22 von Steinberg. Von den billigen Mini-Mischpulten wie von Behringer würde ich abraten. Rauchen stark und klingen nicht sonderlich.
Einen Kopfhörer mit höherem Qualitätsanspruch, wie den AKG K-271 MK II oder ähnlich. Er muss nicht ohrumschließend sein, es hat aber seine Vorteile.
Ein ausreichend langes XLR-Kabel zwischen Mikro und Mischpult.
Einen Tischhalter für das Mikro, ich benutze den MILLENIUM DS100, zusätzlich noch einen Pop-Filter, den gibt es bei Thomann im Bundle mit dem Mikro.
Für die Minimalkonfiguration ohne USB-Anschluss ist die Sache einfach: die beiden Stecker für Mikro und Hörer sind farblich codiert, grün und rosa, und kommen in die entsprechenden Anschlüsse der Soundkarte des PCs. Für die größere Lösung sollte man schon etwas mit Audiotechnik vertraut sein, schwierig ist es aber auch nicht: USB-Audiointerface mit einem USB-Anschluss des PCs verbinden, Mikro über ein XLR-Kabel auf einen Mikro-Eingang des Interfaces, Hörer an Headphone Out des Interfaces oder am PC, bei Kondensator-Mikrophonen das Einschalten der Phantomversorgung nicht vergessen. Wer etwas über Mischpulte lesen möchte, findet an dieser Stelle einen Artikel dazu. Danach sollte die Unwissenheit über die Bedienung eines Pultes kein Hindernis mehr darstellen. So weit die harte Ware.
Software
In der letzten Zeit hat sich auf der Softwareseite ein kostenloser Standard etabliert: Audacity, kostenlos und erstaunlich leistungsfähig. Bezüglich Konfiguration und Bedienung ist in der Site genug zu finden, so dass auch Unerfahrene schnell zu Ergebnissen kommen. Kleine Tücke ist, dass in der Konfiguration von Audacity bei Verwendung eines USB-Pultes oder Wandlers als Ein- und Ausgang der USB Audio Codec gewählt werden muss.
Tatsächlich ist es ein größerer Schritt, wenn man mit diesem Thema noch nicht beleckt ist, aufzunehmen und zu bearbeiten. Nicht erschrecken, nicht abschrecken lassen und die Anleitungen für Audacity durch arbeiten. Es ist nicht so schwierig, wie es auf den ersten Blick aussieht. Audacity zum Aufnehmen zu wählen, hat eine Menge Vorteile, denn man kann nicht nur Patzer oder Seitenblättern herausschneiden, sondern auch später Jingles oder externe Aufnahmen mit hinein mischen, im Prinzip wie in einem “richtigen” Tonstudio. Und nicht vergessen, sich den LAME MP3 Encoder dazu zu laden, um direkt aus Audacity MP3-Dateien erzeugen zu können.
Die wirklichen Knackpunkte
Nun wollte ich nicht detailliert auf die Hardware und Software eingehen, denn dazu finden sich im Netz genug Hilfen zur Auswahl und zur Konfiguration. Die anderen Fragen sind die, wie man einen solchen Podcast gestaltet und welche sonstigen Voraussetzungen wichtig sind. Diese Geschichte fängt mit der akustischen Gestaltung an.
Macht man seine ersten Aufnahmeversuche, wird man einige Merkwürdigkeiten feststellen, an die man zuerst nicht gedacht hatte. Die eine sind Nebengeräusche, da fährt ein LKW am Haus vorbei, der Nachbar geht duschen oder der Tisch macht Geräusche, so bald man sich auch nur minimal bewegt. Von Maus-Clicks ganz zu schweigen, oder der PC-Lüfter ist im Hintergrund zu hören. Die Clicks beim Starten der Aufnahme sind noch das kleinste Problem, die kann man in Audacity (ich nutze n-Track zum Mischen und Goldwave zum Aufnehmen und Bearbeiten) herausschneiden, ebenso Geräusche, die in Sprechpausen entstanden sind. Aber den LKW oder die Dusche eben nicht. Daher empfiehlt sich für das Aufnehmen ein möglichst geschützter Raum, in dem keine Nebengeräusche zu hören sind. Bei mir ist das der Keller, dort habe ich einen stabilen Tisch und sämtliches Equipment, so dass ich nicht auf- oder abzubauen brauche. Und die einzige mögliche Störquelle ist ein Wasserrohr, aber das alles ist berechenbar. Von einem Amerikaner habe ich gelesen, dass er im Abstellraum aufnimmt. Auch eine Variante.
Speaker’s Booth
Die Möglichkeit, sein Studio im Keller zu errichten, ist sicher nahe am Optimalen, weil es dort meistens am ruhigsten ist. Aber dann kommt ein neues Problemchen auf: Raumakustik. Es ist hallig, die nackten Wände eines Kellers sorgen für eine unruhige Akustik, die Stimme verschwimmt. Dazu muss nicht mal ein Keller her, in so manchem größeren Wohnzimmer oder Arbeitszimmer hat man genug Raumhall, der die Verständlichkeit stört. Es klingt einfach schlecht. Bei einem Headset tritt dieser Effekt übrigens nicht so ausgeprägt auf, ein Großmembran-Kondensatormikrophon dagegen lässt selbst einen unruhigen Fuß noch klar in der Aufnahme präsent werden. Dagegen hilft nur eins: Dämmen. Da man im Keller wohl weniger Ärger mit der Dame des Hauses bekommt, wenn man die Wände mit Dämmmatten tapeziert, diese sind ein probates Mittel, bekommt der Keller wieder Attraktivität. Ansonsten helfen Teppiche, Vorhänge oder Polstermöbel. Wie man den Raum nun akustisch trockener bekommt, ist sehr individuell. Ist der Raum groß, ist es günstiger, die Dämmungen auf Schaumplatten oder Sperrholz zu kleben und mittels Holzlatten ein Gestell zu bauen, das die Konstruktion im Raum frei platzierbar macht. So in meinem Keller geschehen. Dann brauchen zwar noch ein oder zwei Wände eine Dämmung, aber es hält sich geldlich und optisch im Rahmen. Tatsächlich sollte man sehen, dass man den Raum akustisch so trocken wie möglich bekommt. Professionelle Studios haben einen Speaker’s Booth, einen kleinen Raum, der akustisch sehr ruhig ist, mit einem Fenster zur Kommunikation. In diese Richtung sollte man möglichst kommen. Es muss übrigens gar nicht so teuer werden, sein Studio auszustatten. Um die Kellerregale zu verstecken und den Raum weiter zu dämmen, habe ich billige Decken von IKEA und eine Vorhangstange verwendet. Macht das Kellerstudio wohnlicher und akustisch angenehmer. Die Dämmmatten kann man von Thomann kaufen, manche Schaumstoffhändler haben diese aber auch als Verpackungsmaterial.
Sind diese Fragen gelöst und man vielleicht sogar seinen eigenen Speaker’s Booth, bleibt noch das Material als Störquelle. Viele PCs haben einen Lüfter, der laut und vernehmlich tönt, was dann in der Aufnahme nicht zu überhören ist. Ideal sind daher Netbooks und Nettops, die keinen Lüfter haben, oder nur einen sehr kleinen und leisen. Aber auch professionelle PCs, die gebraucht schon um die 150 Euro zu bekommen sind, können erstaunlich leise sein. Mein Fujitsu ESPRIMO E5915 jault beim Verbinden mit dem Stromnetz einmal auf, danach ist er aber nicht mehr zu hören. Bestehen diese materiellen Möglichkeiten nicht, kann man mit Hilfe eines Reparatur-fähigen PC-Händlers versuchen, seinen Rechner leiser zu bekommen, zum Beispiel durch Montage von Gummidämpfern für Lüfter und Festplatten, oder durch Austausch des Netzteiles. Letztes Mittel ist ein großer Karton, der innen mit Dämmplatten beklebt wird, aber noch Platz für den Wärmeaustausch lässt, so dass der PC sein eigenes Speaker’s Booth bekommt und nicht so sehr durch Geräusche stört.
Problem gelöst, neue Probleme
Hat man das alles hin bekommen, alle Hardware und Software am Laufen, sein schönes und inspirierendes Plätzchen, dann, ja dann geht es an die Inhalte selbst. Vorausgesetzt, man hat es Ideen, was man in seinem Podcast machen möchte, können ein paar Gedanken über die Ausgestaltung nicht falsch sein.
Es gibt Leute, die schreiben sich für eine halbe Stunde Sprechen drei Stichworte auf eine Karteikarte und leisten sich nicht ein einziges Äh. Andere schreiben den kompletten Text aus und verhaspeln sich doch achtmal. Ich denke, es kommt auf den Text an. Ist man mit den Themen sehr vertraut, ist freies Sprechen mit einiger Übung möglich. Ablesen von Text verleitet zu eher monotonem Sprechen, was absolut kontraproduktiv ist, denn die Hörer schlafen ein oder schalten ab. Man muss an diesem Punkt seine eigene Wohlfühlgrenze ausloten, wie viel an Inhalt und Text man vorproduziert. Zu bedenken ist, dass man den Text dann auch vor Augen haben muss, so kommen die Probleme mit raschelndem Papier oder Maus- und Tastaturgeräuschen wieder in den Vordergrund. Und man kann nicht alles heraus schneiden, was stört, wenn es hinter der Sprache liegt. Optimal ist es, wenn die Notizen auf eine DIN A4-Seite passen, oder auf einen Bildschirm. Und das groß genug, denn je größer die Schrift, desto weniger Gefahr sich zu verhaspeln oder im Text zu verlieren. Ausprobieren.
Nichts ist gefährlicher als eine langweilige Stimmführung, nichts ist nerviger als eine Wiedergabe mit Pop-Geräuschen bei den explosiven Konsonanten oder ein zu leiser Sprecher, nichts ist einschläfernder als eine Kettung von Bandwurmsätzen oder eine Sprache, die von Substantiven überquillt, Beamtensprache. Den ersten Punkt muss man üben und man muss sich trauen, variabler und mit weiterer Stimmführung als vielleicht im Alltag zu sprechen. Die Pop-Geräusche kann der Filter vermeiden, man sollte aber auf dem Abstand zum Mikro achten, eine Handspanne ist meistens am besten, für den Pegel die Anzeigen in der Aufnahmesoftware beachten, der Pegel sollte so bei -3 bis -6dB liegen. Ein Software-Kompressor (soft knee) in der Aufnahmesoftware hilft, Übersteuerungen zu vermeiden. Bleibt die Sprache als solche, daran muss man, wie bei den Webinaren schon geschildert, arbeiten. Die Texte sollten abwechselungsreich und farbig, aber nicht grell oder schrill sein.
Blieben noch die übrigen Gestaltungsmöglichkeiten. Jingles, also Musiksequenzen oder andere Einstreuungen, sind hilfreich für den Wiedererkennungswert und wecken ein wenig, brechen die längeren Textsequenzen auf. Aber Finger weg von urheberrechtlich geschütztem Material von CDs oder aus dem Netz, das kann teuer werden. Entweder nach freien Jingles suchen, oder selbst welche gestalten. Musiker an Gitarre oder Klavier/Keyboard sind hier besser dran. Ansonsten sind der Phantasie kaum Grenzen gesetzt: Außenaufnahmen mit einem Diktiergerät, Familie oder Freunde um Abschnittsbeiträge bitten, den Text mit unauffälligen Sounds unterlegen. Also z. B. Musik ohne Soloinstrumente oder Gesang, möglichst gleichförmig. Hier kommt die Kreativität ins Spiel und der Bereich, wo der individuelle Podcast gestaltet wird.
Vom eigentlichen Thema ganz abgesehen. Denn das bleibt das Schwierigste.
https://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.png00Rainer Böttchershttps://textura.rainerboettchers.de/wp-content/uploads/2023/03/textura-media-logo-only.pngRainer Böttchers2022-02-26 20:09:372024-02-26 20:15:06Podcast Stufe Eins
We may request cookies to be set on your device. We use cookies to let us know when you visit our websites, how you interact with us, to enrich your user experience, and to customize your relationship with our website.
Click on the different category headings to find out more. You can also change some of your preferences. Note that blocking some types of cookies may impact your experience on our websites and the services we are able to offer.
Essential Website Cookies
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, refusing them will have impact how our site functions. You always can block or delete cookies by changing your browser settings and force blocking all cookies on this website. But this will always prompt you to accept/refuse cookies when revisiting our site.
We fully respect if you want to refuse cookies but to avoid asking you again and again kindly allow us to store a cookie for that. You are free to opt out any time or opt in for other cookies to get a better experience. If you refuse cookies we will remove all set cookies in our domain.
We provide you with a list of stored cookies on your computer in our domain so you can check what we stored. Due to security reasons we are not able to show or modify cookies from other domains. You can check these in your browser security settings.
Other external services
We also use different external services like Google Webfonts, Google Maps, and external Video providers. Since these providers may collect personal data like your IP address we allow you to block them here. Please be aware that this might heavily reduce the functionality and appearance of our site. Changes will take effect once you reload the page.
Google Webfont Settings:
Google Map Settings:
Google reCaptcha Settings:
Vimeo and Youtube video embeds:
Privacy Policy
You can read about our cookies and privacy settings in detail on our Privacy Policy Page.
 In der Tat ist es bei längeren und komplexen Themen und Texten sinnvoll, den Beitrag vorzuschreiben. Sinnvoll ist es nicht, ihn so zu schreiben wie sonstigen Text, also schön und optisch ansprechend, und mit optimalem Schrifteindruck. Denn das Ziel bei diesem Text ist es, den Text möglichst fehlerfrei und fließend lesen zu können. Der Text soll das Sprechen unterstützen. Dafür gibt es ein paar Stellschrauben, die werden in Büchern auch genannt. An einigen Stellen bin ich erst durch einen einzelnen amerikanischen Kollegen zurecht gekommen. Das Ganze in Listenform.
In der Tat ist es bei längeren und komplexen Themen und Texten sinnvoll, den Beitrag vorzuschreiben. Sinnvoll ist es nicht, ihn so zu schreiben wie sonstigen Text, also schön und optisch ansprechend, und mit optimalem Schrifteindruck. Denn das Ziel bei diesem Text ist es, den Text möglichst fehlerfrei und fließend lesen zu können. Der Text soll das Sprechen unterstützen. Dafür gibt es ein paar Stellschrauben, die werden in Büchern auch genannt. An einigen Stellen bin ich erst durch einen einzelnen amerikanischen Kollegen zurecht gekommen. Das Ganze in Listenform. Ein Tisch-Bücherständer leistet gute Dienste beim Einsprechen im Sitzen. Mit etwas Geschick bekommt man sogar drei Seiten platziert. Mit einem solchen Ständer, ein Notenständer oder ein Klemmbrett hilft auch, hat man kein Papier in der Hand und raschelt nicht herum. Jedenfalls bleibt in meinen Händen kein Papier still. YMMV. Blattwechsel schneidet man später heraus oder nimmt in Etappen auf.
Ein Tisch-Bücherständer leistet gute Dienste beim Einsprechen im Sitzen. Mit etwas Geschick bekommt man sogar drei Seiten platziert. Mit einem solchen Ständer, ein Notenständer oder ein Klemmbrett hilft auch, hat man kein Papier in der Hand und raschelt nicht herum. Jedenfalls bleibt in meinen Händen kein Papier still. YMMV. Blattwechsel schneidet man später heraus oder nimmt in Etappen auf. Generell bin ich vom Einsprechen im Sitzen abgegangen.
Generell bin ich vom Einsprechen im Sitzen abgegangen.  Obwohl es etwas mystisch erscheint, es macht einen großen Unterschied, ob man beim Sprechen sitzt oder steht. Die Atmung verändert sich, im Stehen hat man die Hände frei, kann etwas agieren, die Sprache ist freier. Nimmt man vorwiegend oder nur im eigenen Wohnraum ein, ist ein Orchesterpult optimal. Auf diesem steht das Manuskript, an den oberen Rand kommt eine Klemme für das Mikro. An dieser Klemme findet dann noch gleich der Pop-Schutz Halt. Beide Klemmen stammen von K&M, die große Version hat noch den Vorteil, dass sie fast beliebig positioniert werden kann. Erhältlich beim Musikhändler des Vertrauens oder bei Thomann. Hier die einfache und hier die große Klemme.
Obwohl es etwas mystisch erscheint, es macht einen großen Unterschied, ob man beim Sprechen sitzt oder steht. Die Atmung verändert sich, im Stehen hat man die Hände frei, kann etwas agieren, die Sprache ist freier. Nimmt man vorwiegend oder nur im eigenen Wohnraum ein, ist ein Orchesterpult optimal. Auf diesem steht das Manuskript, an den oberen Rand kommt eine Klemme für das Mikro. An dieser Klemme findet dann noch gleich der Pop-Schutz Halt. Beide Klemmen stammen von K&M, die große Version hat noch den Vorteil, dass sie fast beliebig positioniert werden kann. Erhältlich beim Musikhändler des Vertrauens oder bei Thomann. Hier die einfache und hier die große Klemme.